Having multiple environments is important to build a continuous integration/deployment pipeline and be able to reproduce bugs in production with ease but this comes at price. In order to reduce cost of AWS infrastructure, instances which are running 24/7 unnecessarily (sandbox & staging environments) must be shut down outside of regular business hours.
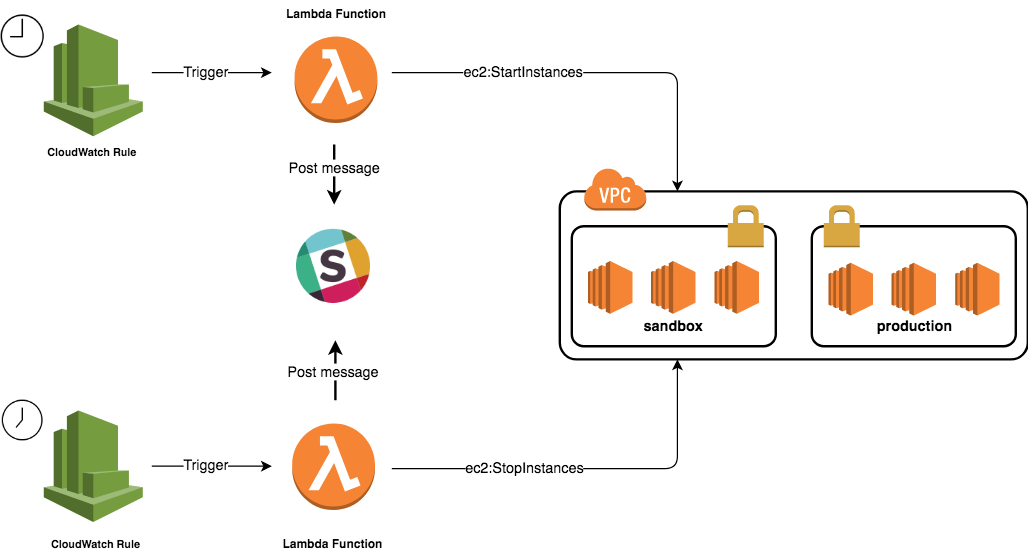
The figure below describes an automated process to schedule, stop and start instances to help cutting costs. The solution is a perfect example of using Serverless computing.
2 Lambda functions will be created, they will scan all environments looking for a specific tag. The tag we use is named ‘Environment’. Instances without an Environment tag will not be affected:
for _, reservation := range res.Reservations { for _, instance := range reservation.Instances { for _, tag := range instance.Tags { if *tag.Key == "Name" { instances = append(instances, Instance{ ID: *instance.InstanceId, Name: *tag.Value, }) } } } }
return instances, nil }
The StartEnvironment function will query the StartInstances method with the list of instance ids returned by the previous function:
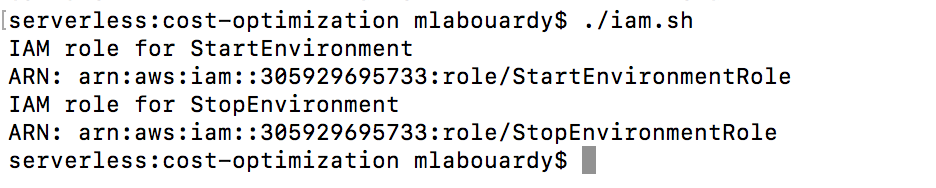
Finally, create an IAM role for each function and attach the above policies:
1 2 3 4 5 6 7 8 9 10 11 12 13
#!/bin/bash
echo "IAM role for StartEnvironment" arn=$(aws iam create-policy --policy-name StartEnvironment --policy-document file://start/policy.json | jq -r '.Policy.Arn') result=$(aws iam create-role --role-name StartEnvironmentRole --assume-role-policy-document file://role.json | jq -r '.Role.Arn') aws iam attach-role-policy --role-name StartEnvironmentRole --policy-arn $arn echo "ARN: $result"
echo "IAM role for StopEnvironment" arn=$(aws iam create-policy --policy-name StopEnvironment --policy-document file://stop/policy.json | jq -r '.Policy.Arn') result=$(aws iam create-role --role-name StopEnvironmentRole --assume-role-policy-document file://role.json | jq -r '.Role.Arn') aws iam attach-role-policy --role-name StopEnvironmentRole --policy-arn $arn echo "ARN: $result"
The script will output the ARN for each IAM role:
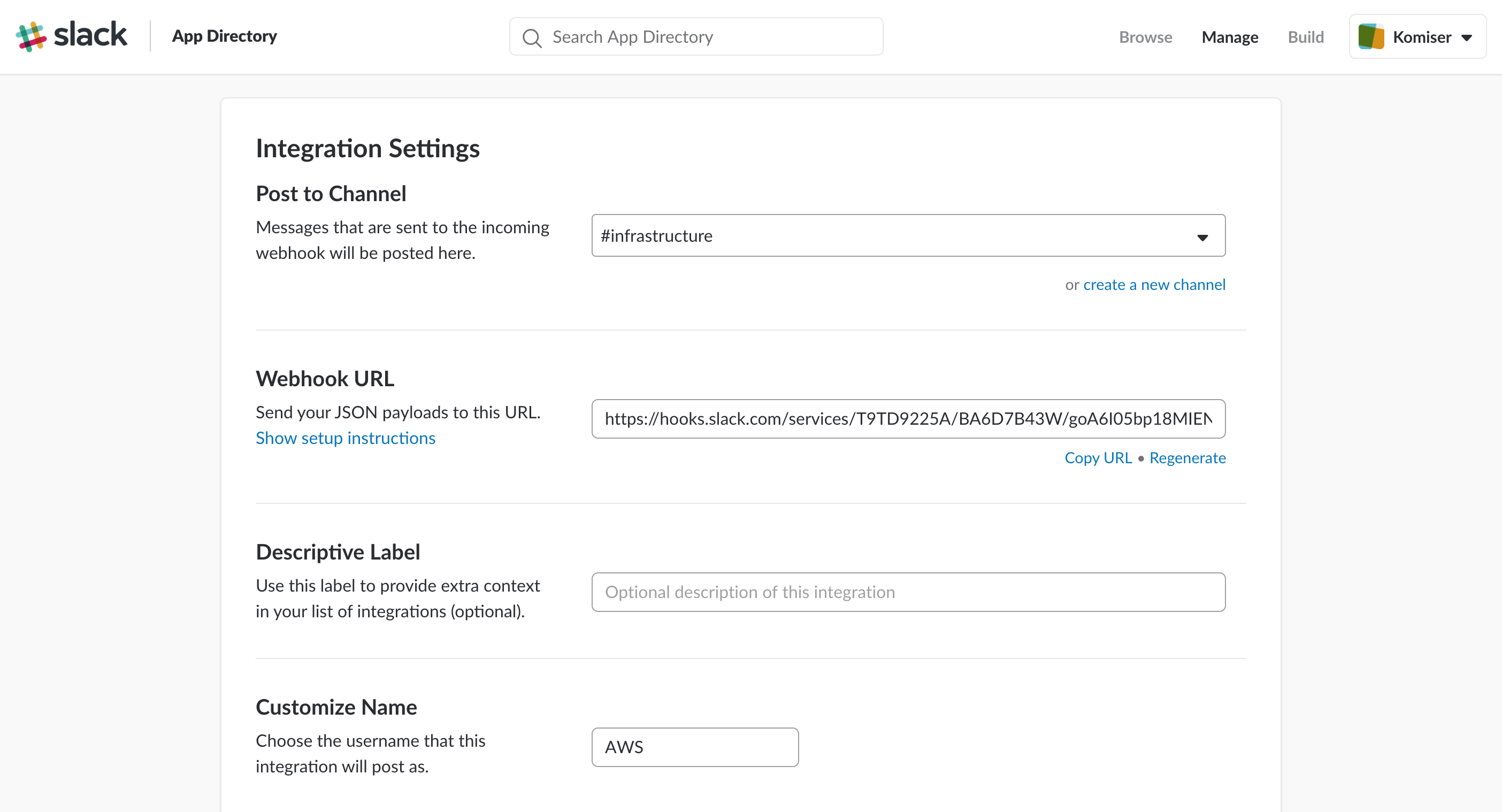
Before jumping to deployment part, we need to create a Slack WebHook to be able to post messages to Slack channel:
Next, use the following script to deploy your functions to AWS Lambda (make sure to replace the IAM roles, Slack WebHook token & the target environment):
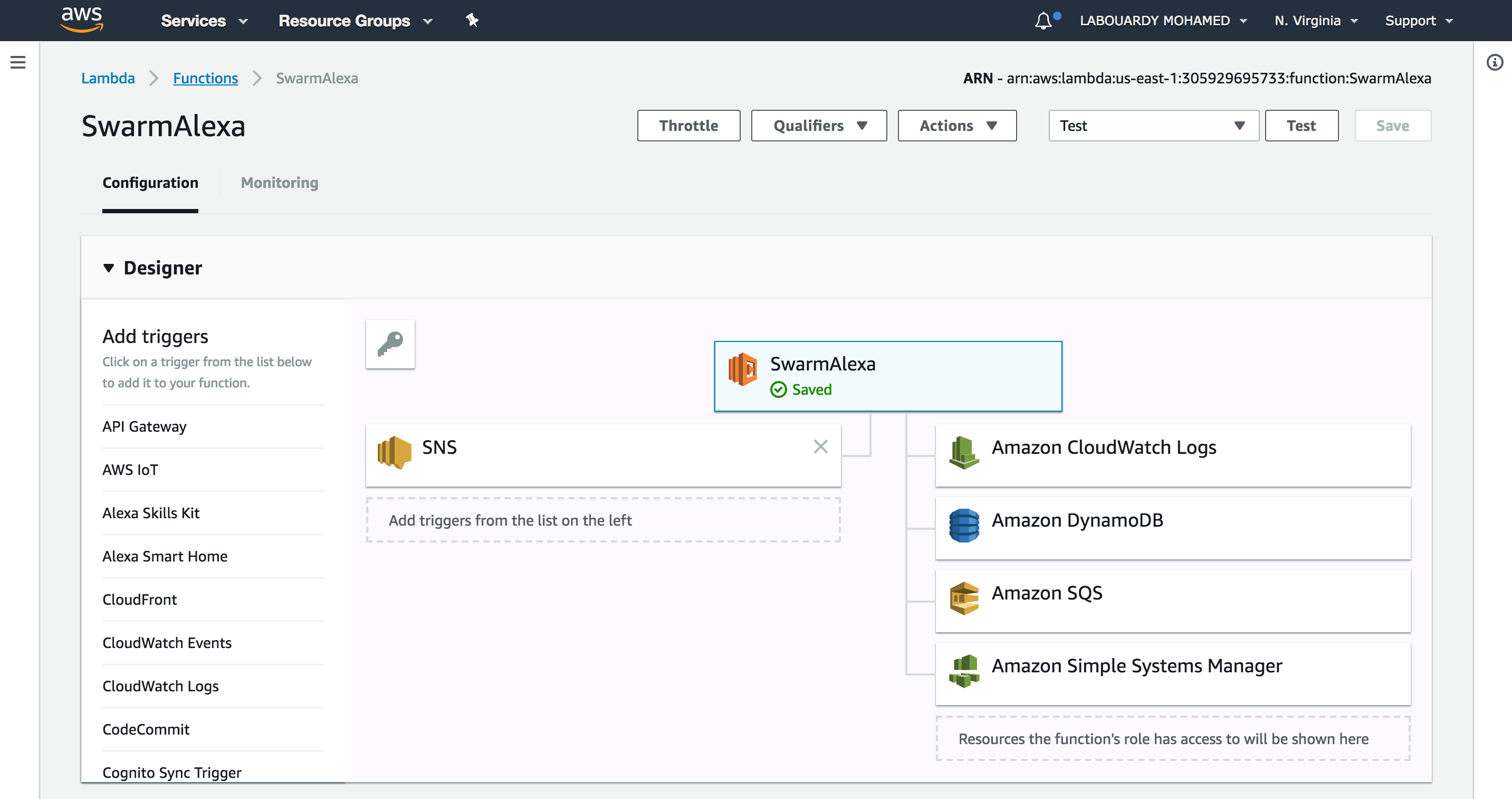
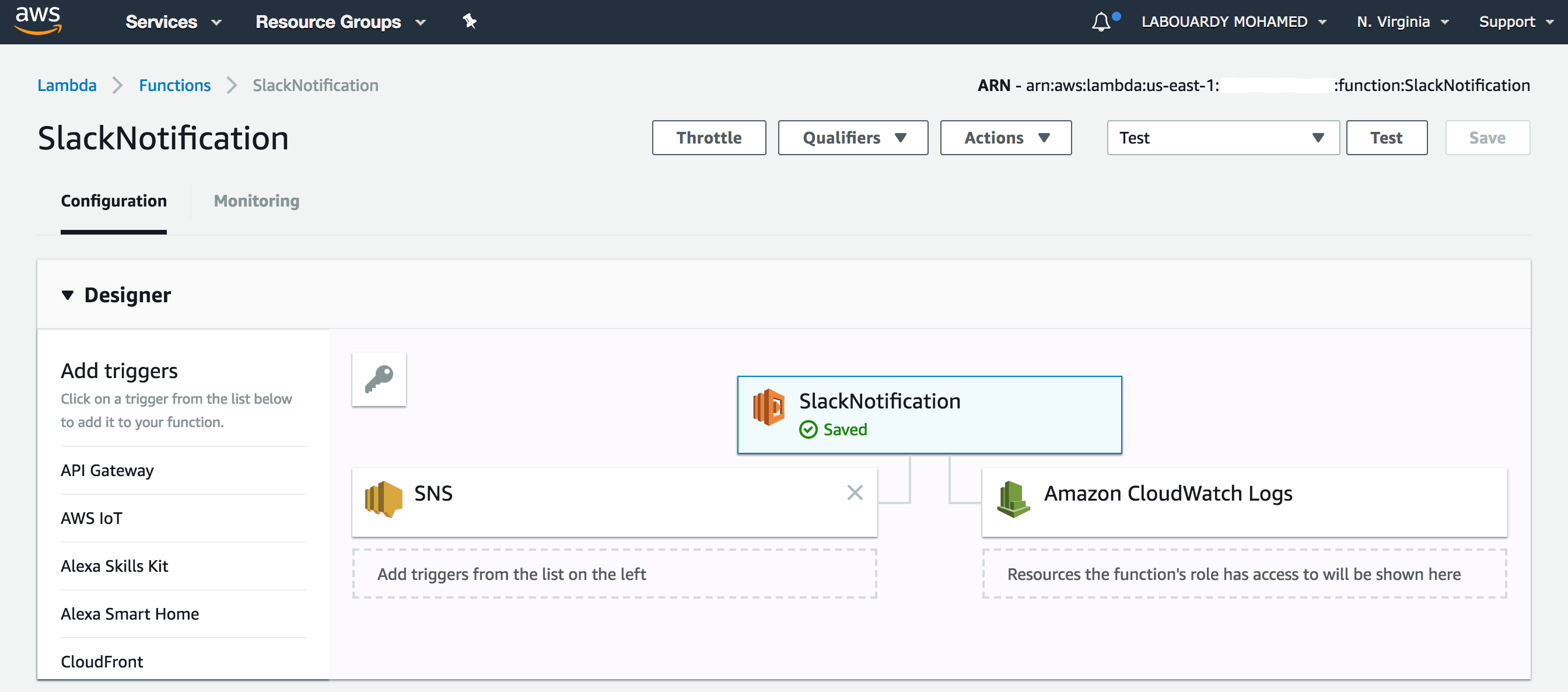
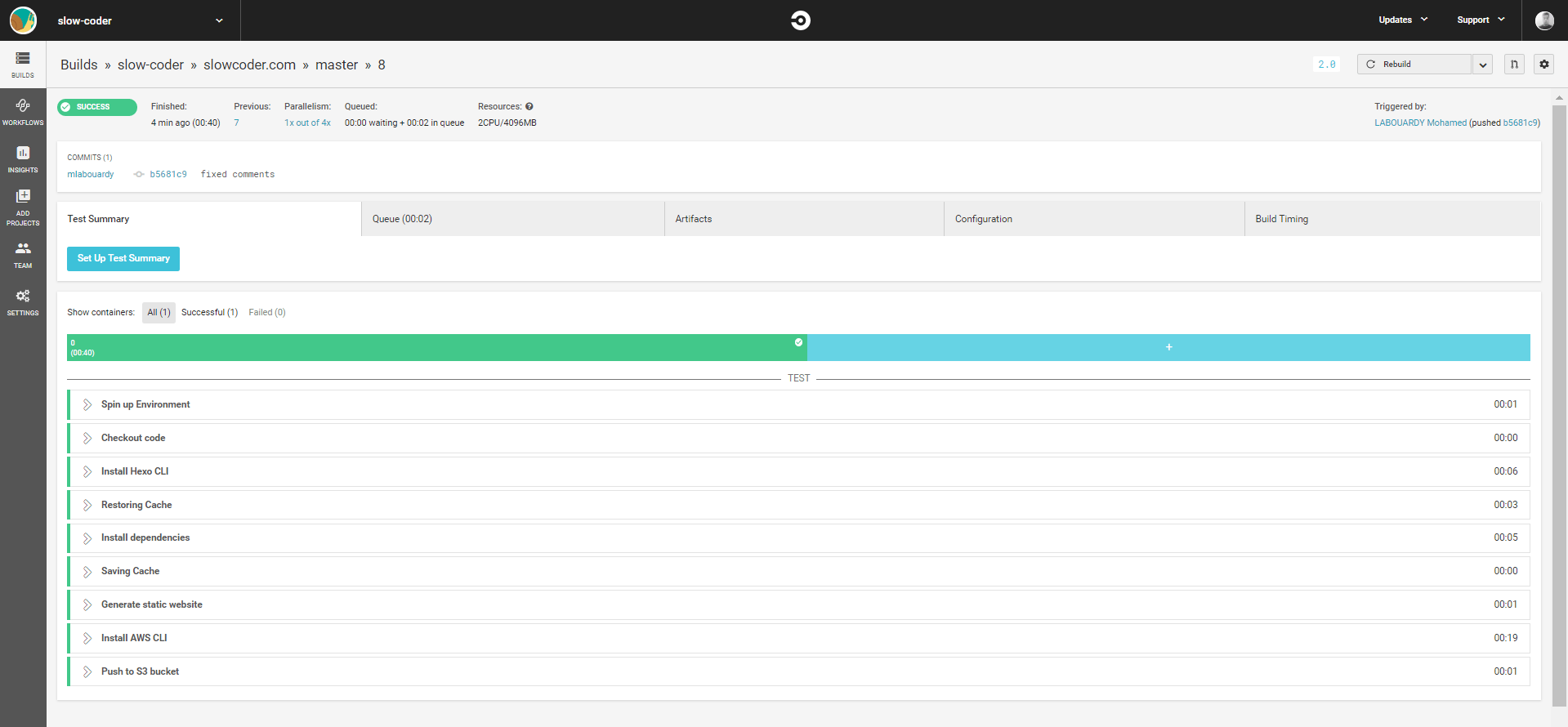
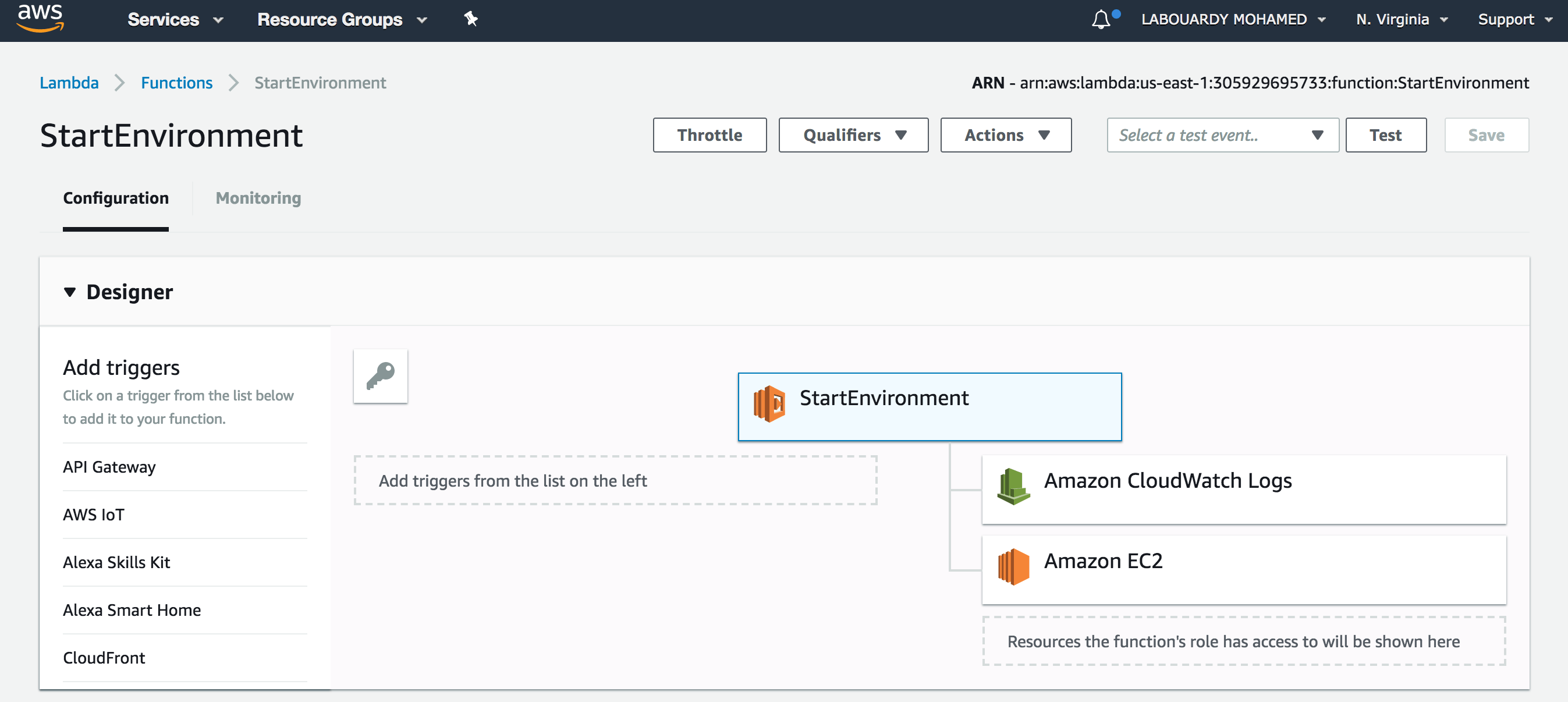
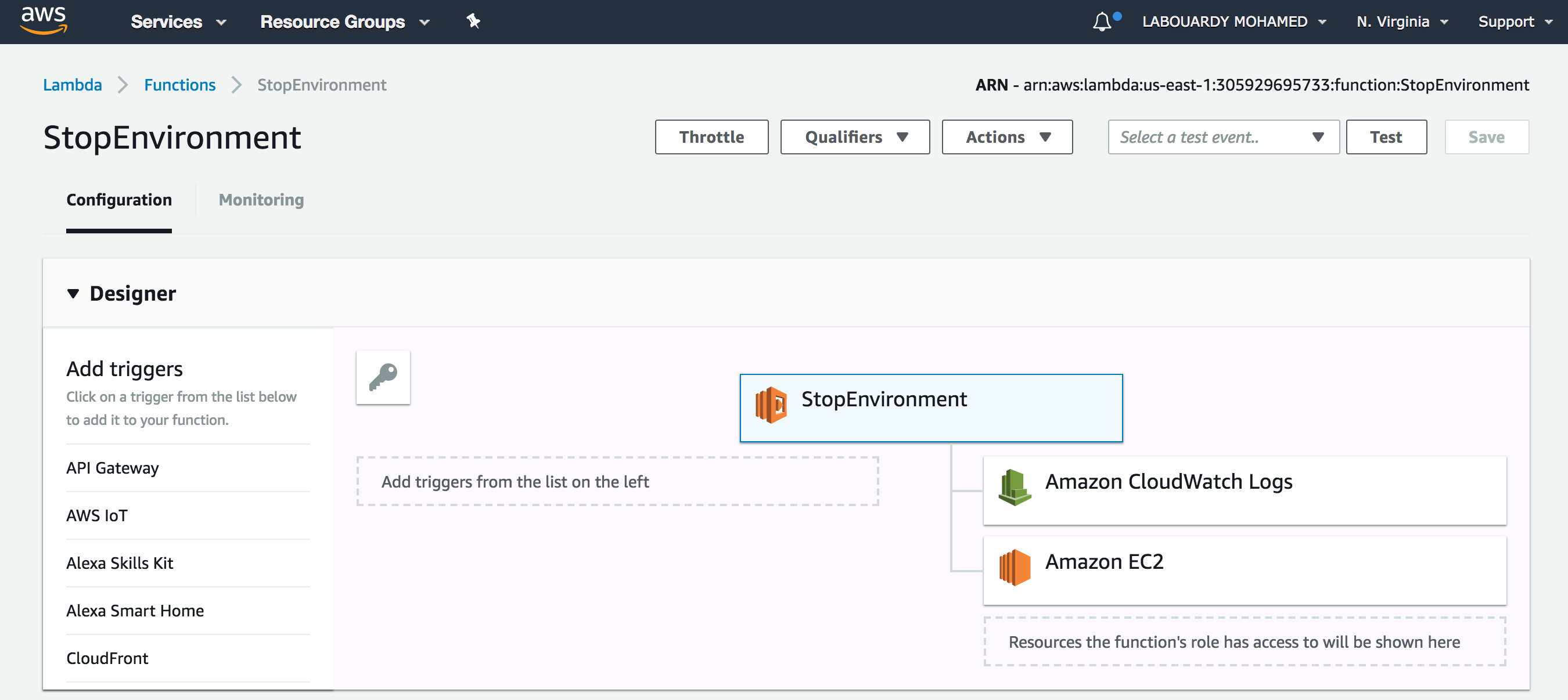
Once deployed, if you sign in to AWS Management Console, navigate to Lambda Console, you should see both functions has been deployed successfully:
StartEnvironment:
StopEnvironment:
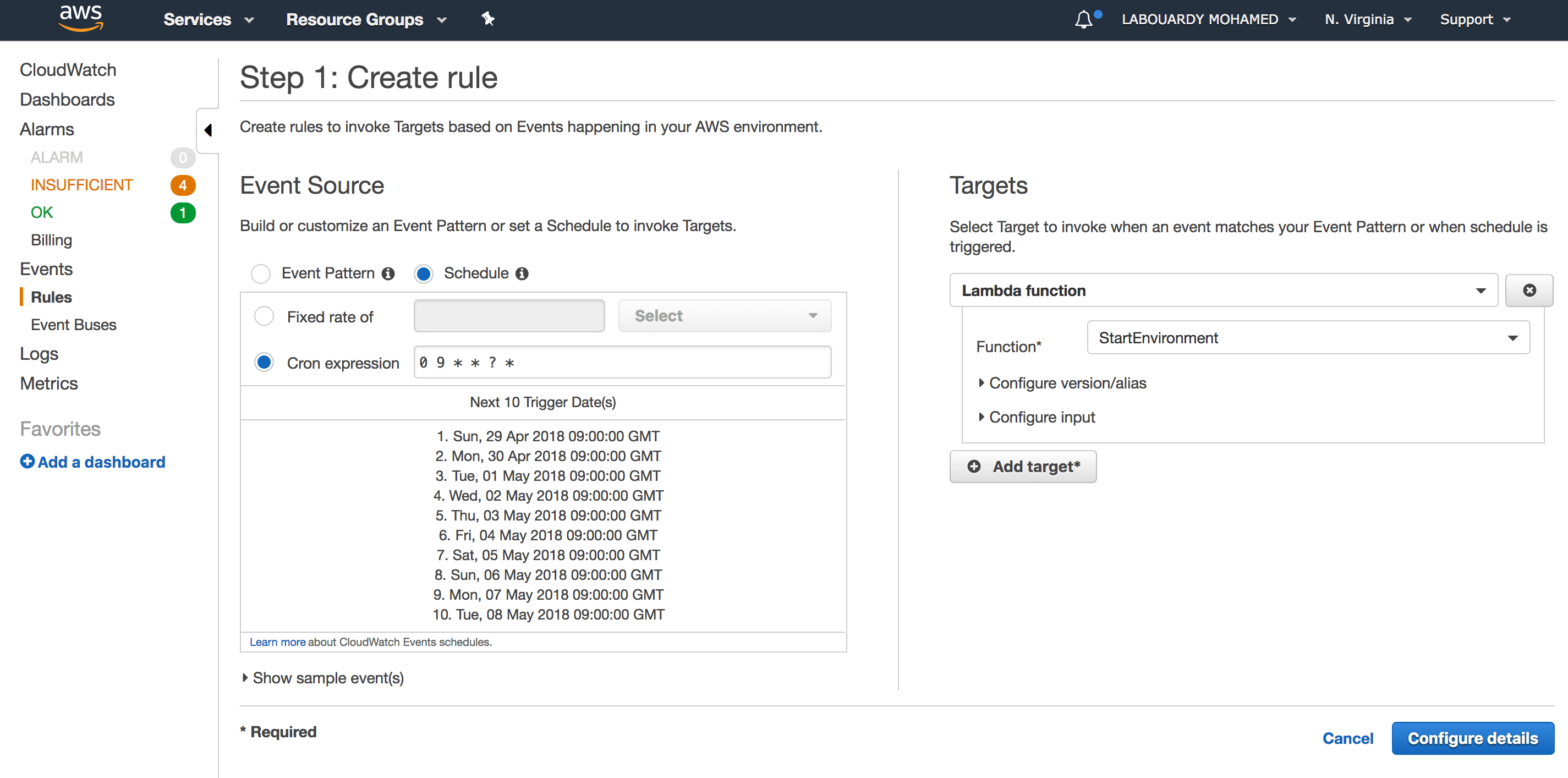
To further automate the process of invoking the Lambda function at the right time. AWS CloudWatch Scheduled Events will be used.
Create a new CloudWatch rule with the below cron expression (It will be invoked everyday at 9 AM):
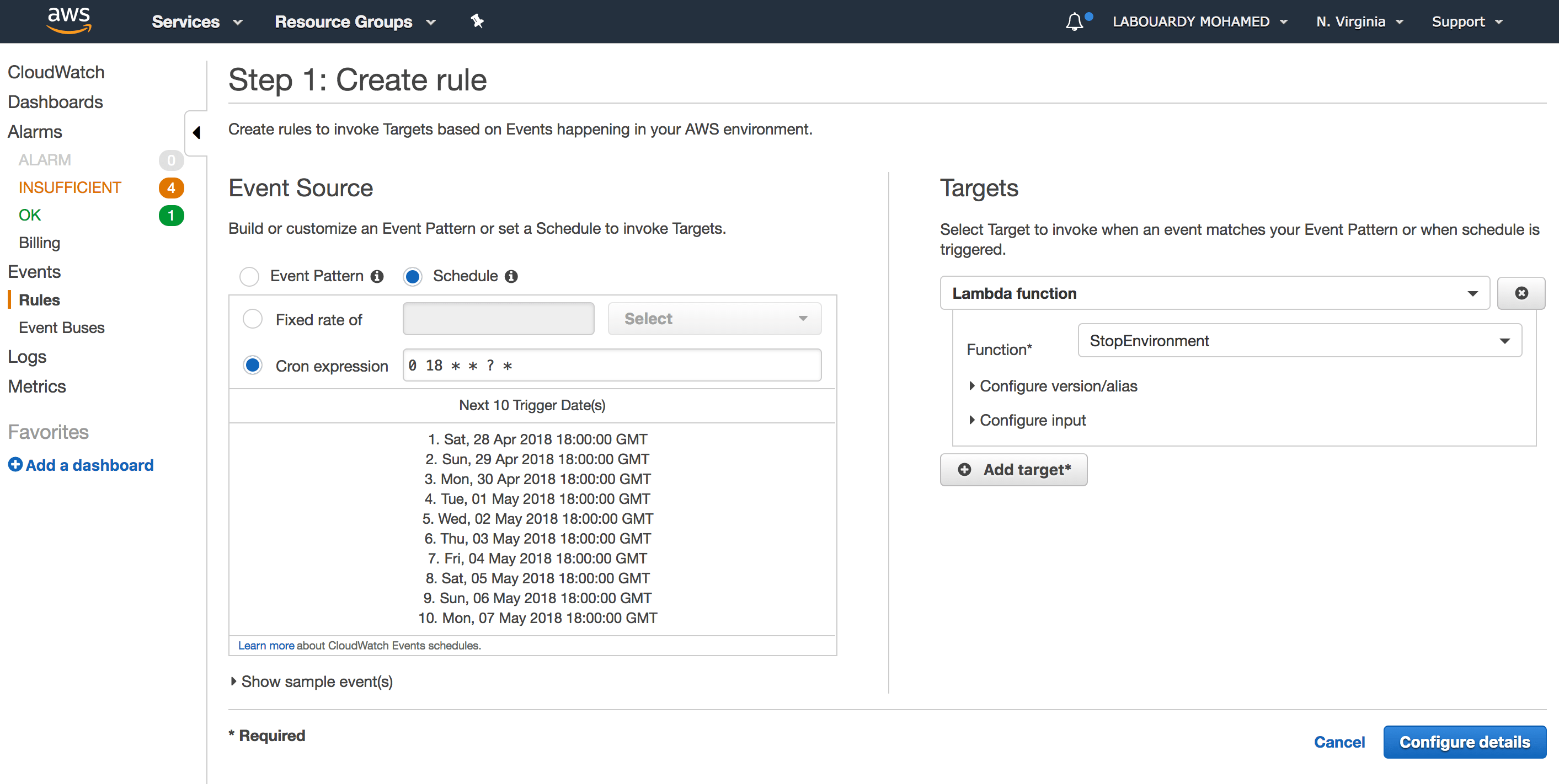
And another rule to stop the environment at 6 PM:
Note: All times are GMT time.
Testing:
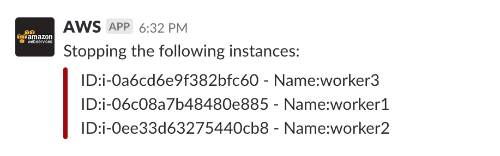
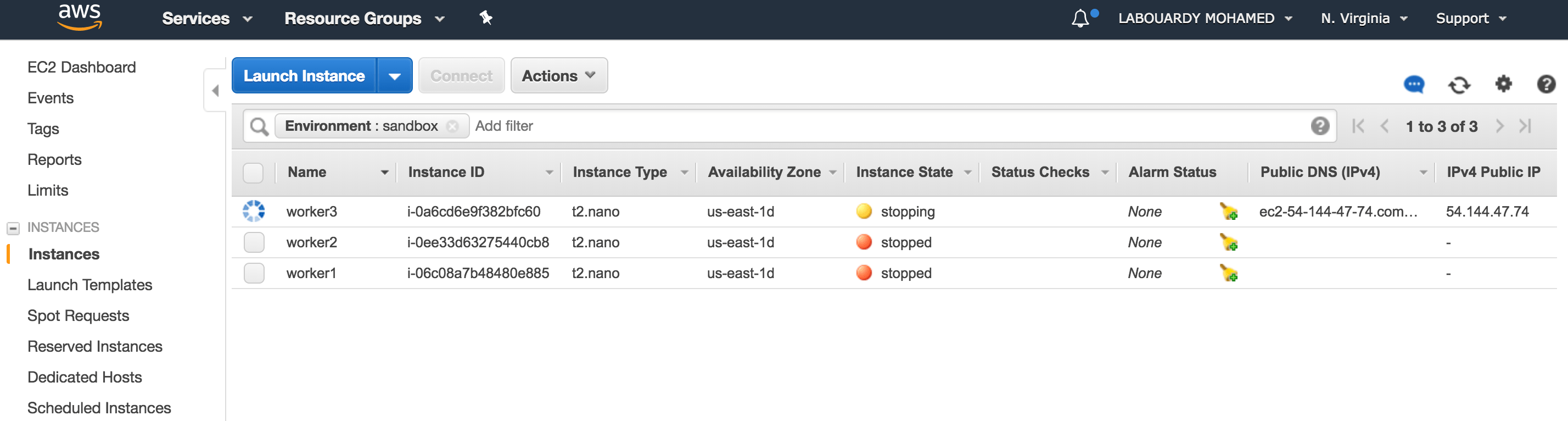
a – Stop Environment
Result:
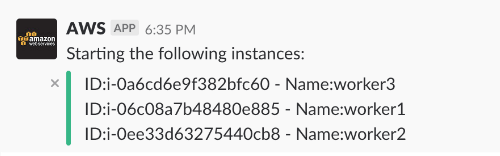
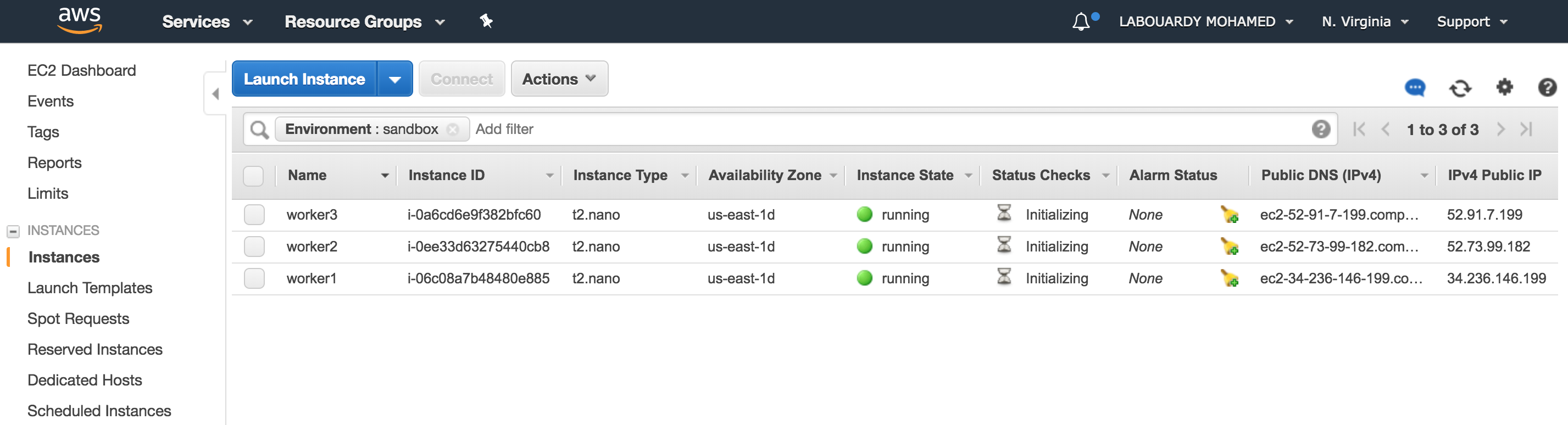
b – Start Environment
Result:
The solution is easy to deploy and can help reduce operational costs.
Full code can be found on my GitHub. Make sure to drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.
Serverless and Containers changed the way we leverage public clouds and how we write, deploy and maintain applications. A great way to combine the two paradigms is to build a voice assistant with Alexa based on Lambda functions – written in Go – to deploy a Docker Swarm cluster on AWS.
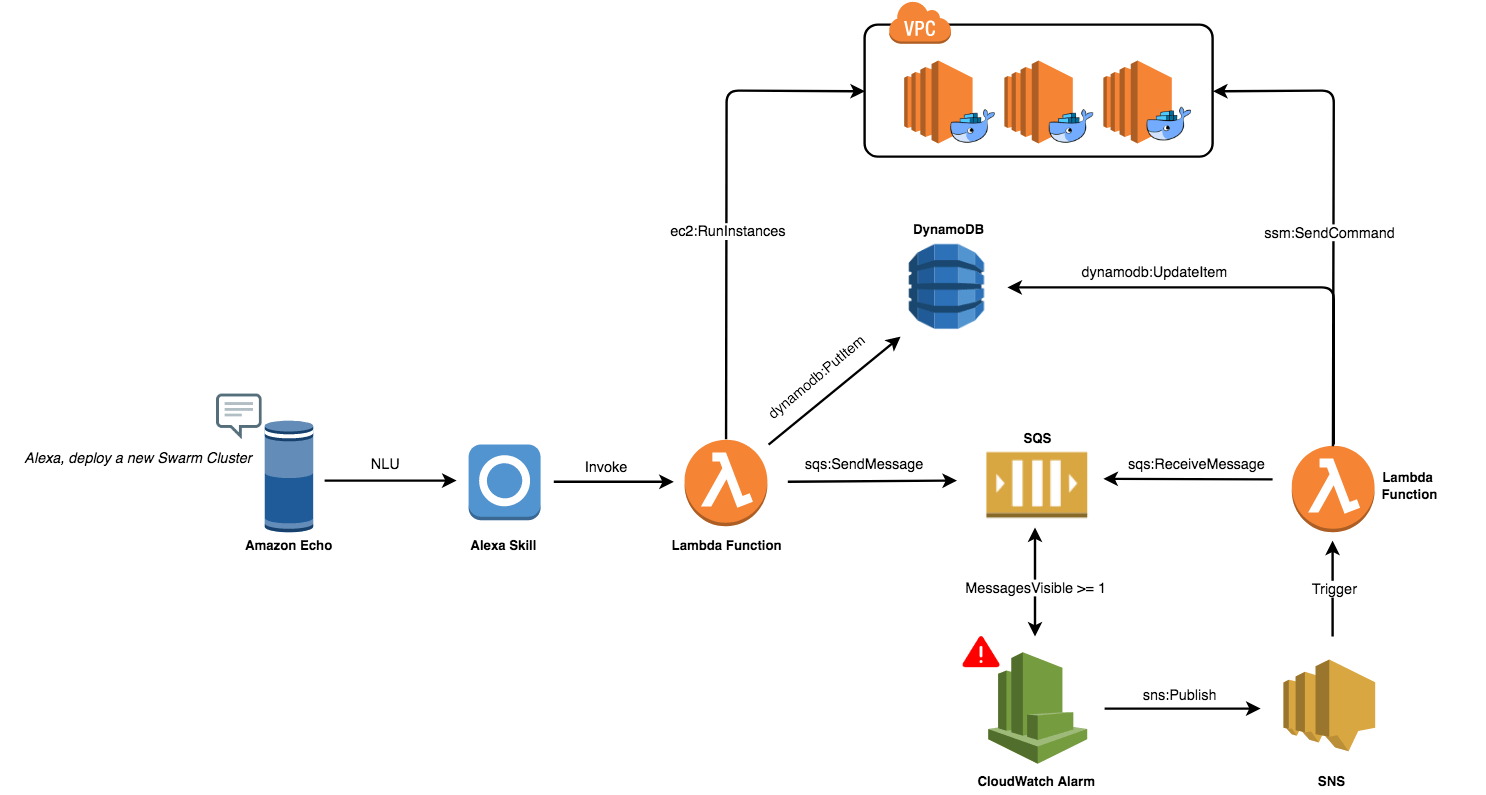
The figure below shows all components needed to deploy a production-ready Swarm cluster on AWS with Alexa.
A user will ask Amazon Echo to deploy a Swarm Cluster:
Echo will intercept the user’s voice command with built-in natural language understanding and speech recognition. Convey them to the Alexa service. A custom Alexa skill will convert the voice commands to intents:
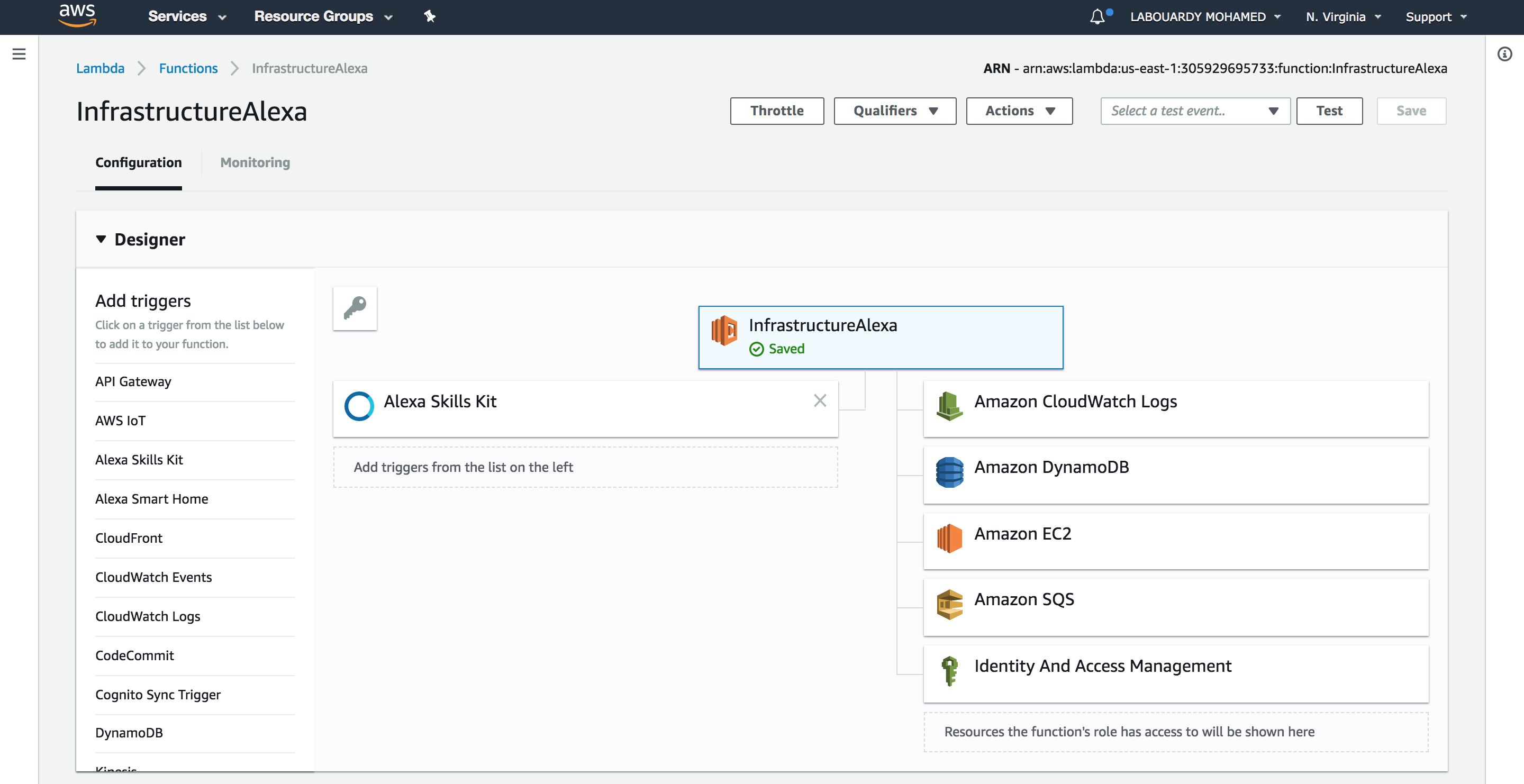
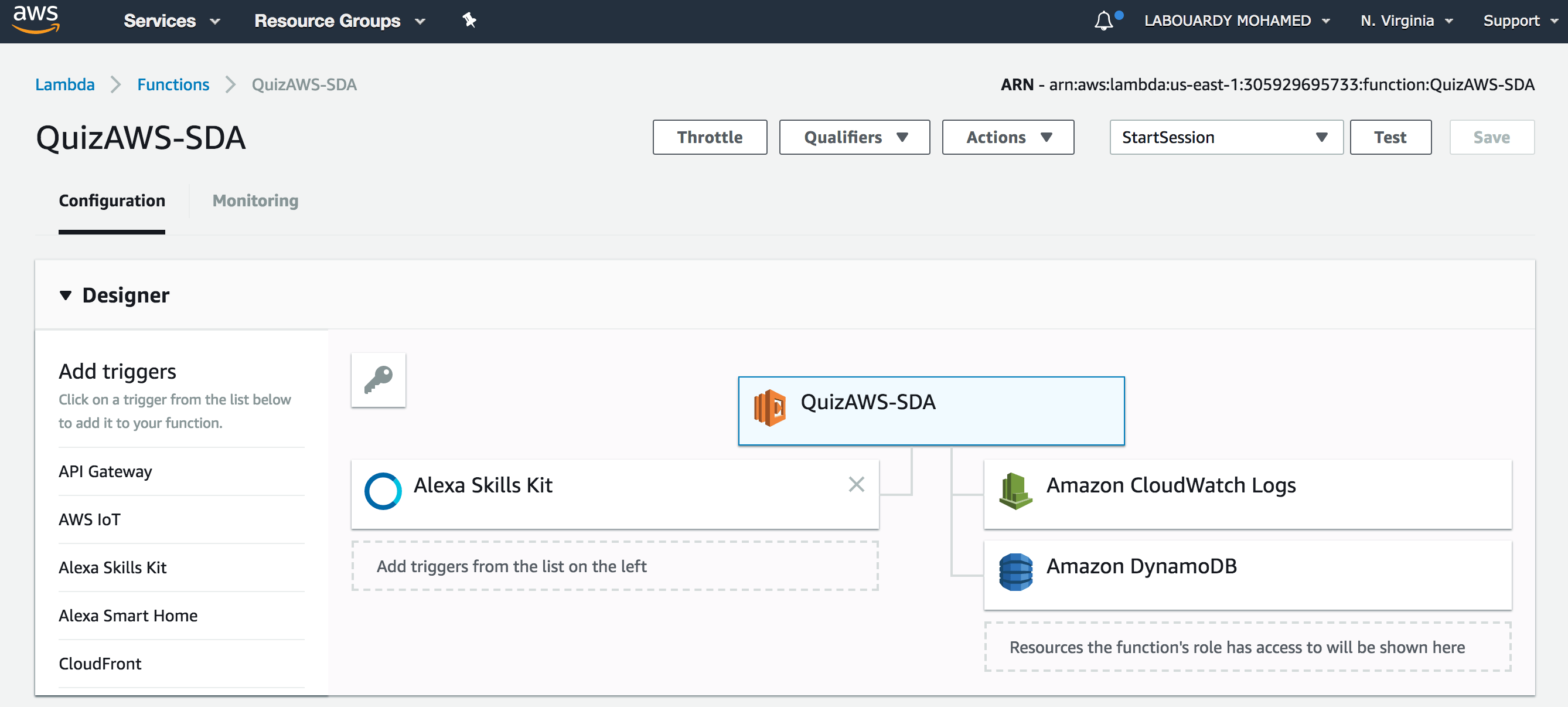
The Alexa skill will trigger a Lambda function for intent fulfilment:
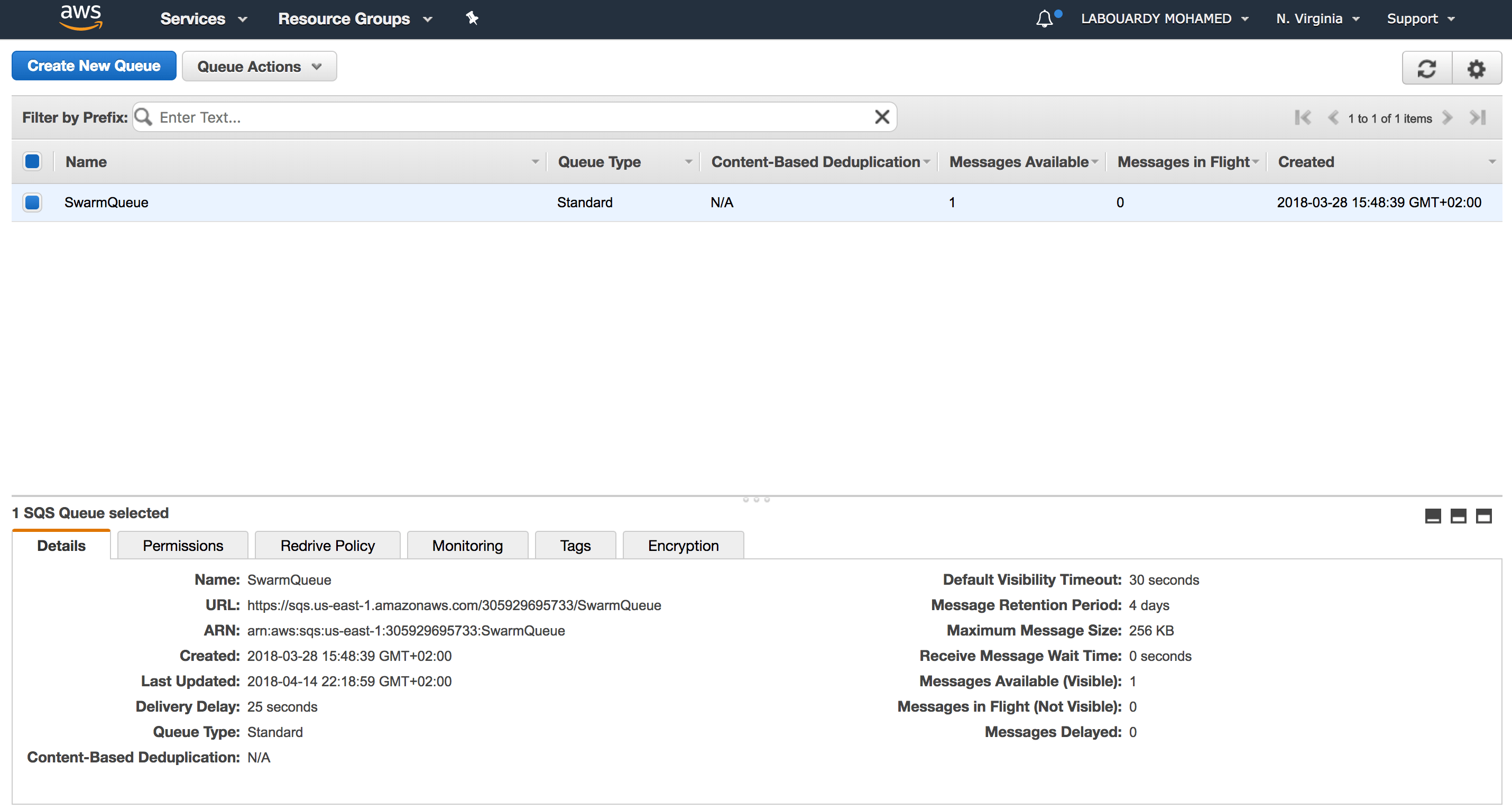
The Lambda Function will use the AWS EC2 API to deploy a fleet of EC2 instances from an AMI with Docker CE preinstalled (I used Packer to bake the AMI to reduce the cold-start of the instances). Then, push the cluster IP addresses to a SQS:
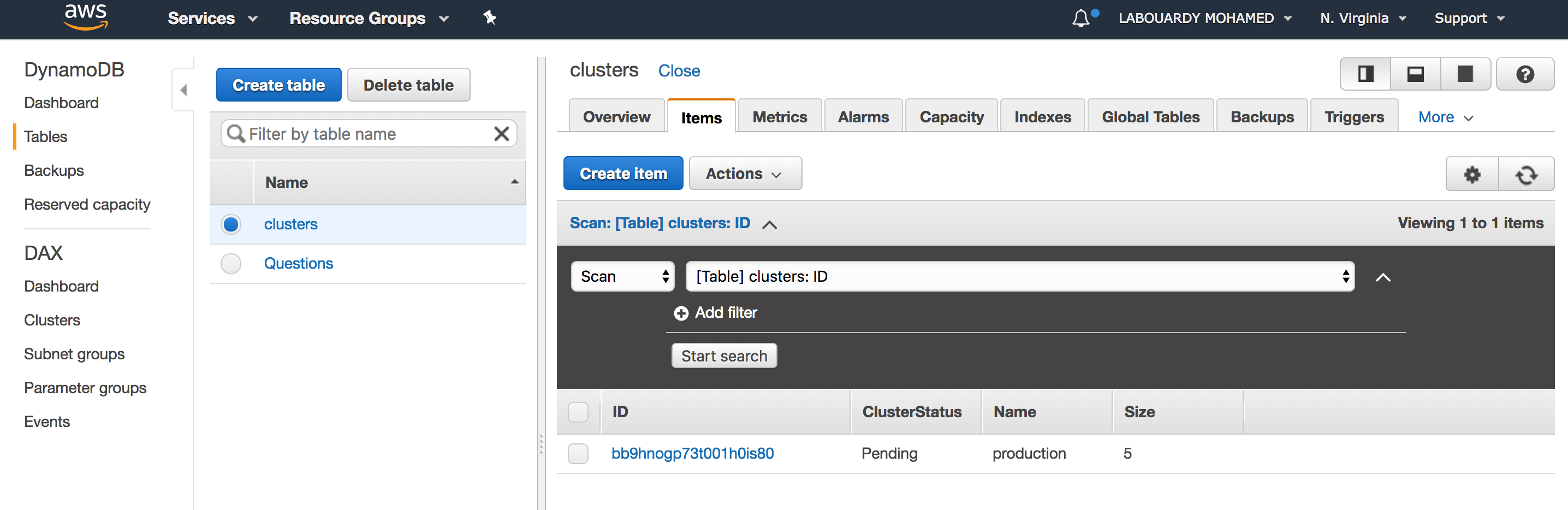
Next, the function will insert a new item to a DynamoDB table with the current state of the cluster:
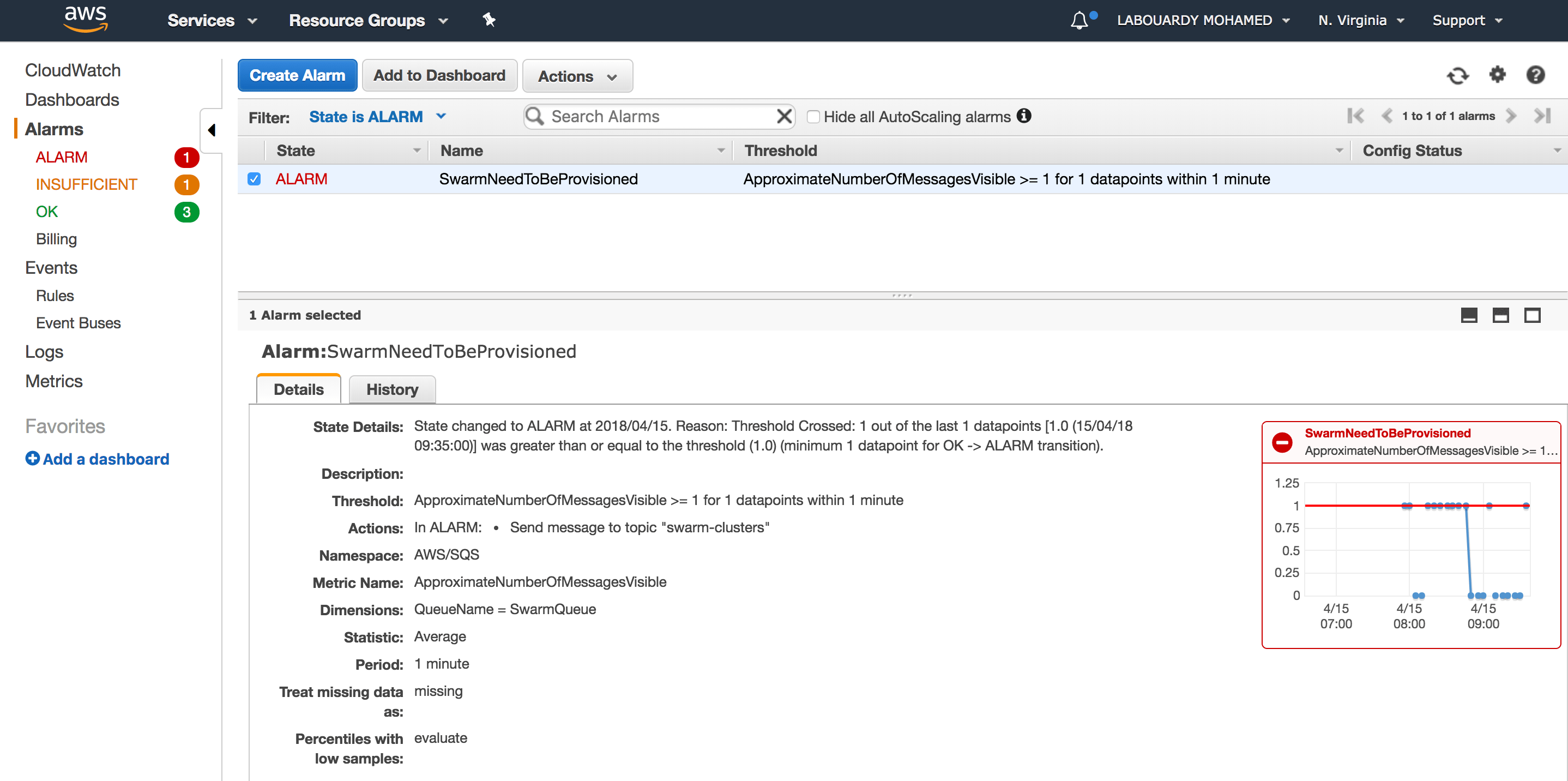
Once the SQS received the message, a CloudWatch alarm (it monitors the ApproximateNumberOfMessagesVisible parameter) will be triggered and as a result it will publish a message to an SNS topic:
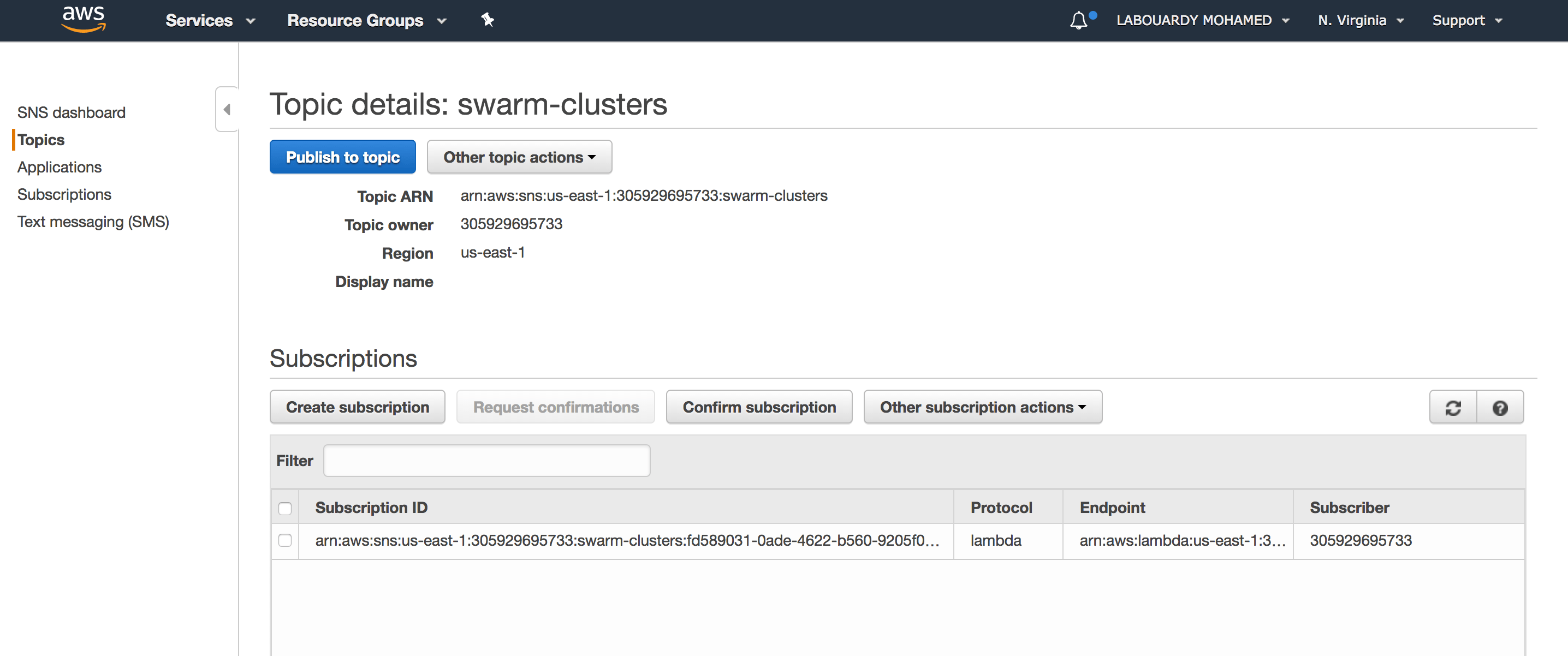
The SNS topic triggers a subscribed Lambda function:
The Lambda function will pull the queue for a new cluster and use the AWS System Manager API to provision a Swarm cluster on the fleet of EC2 instances created earlier:
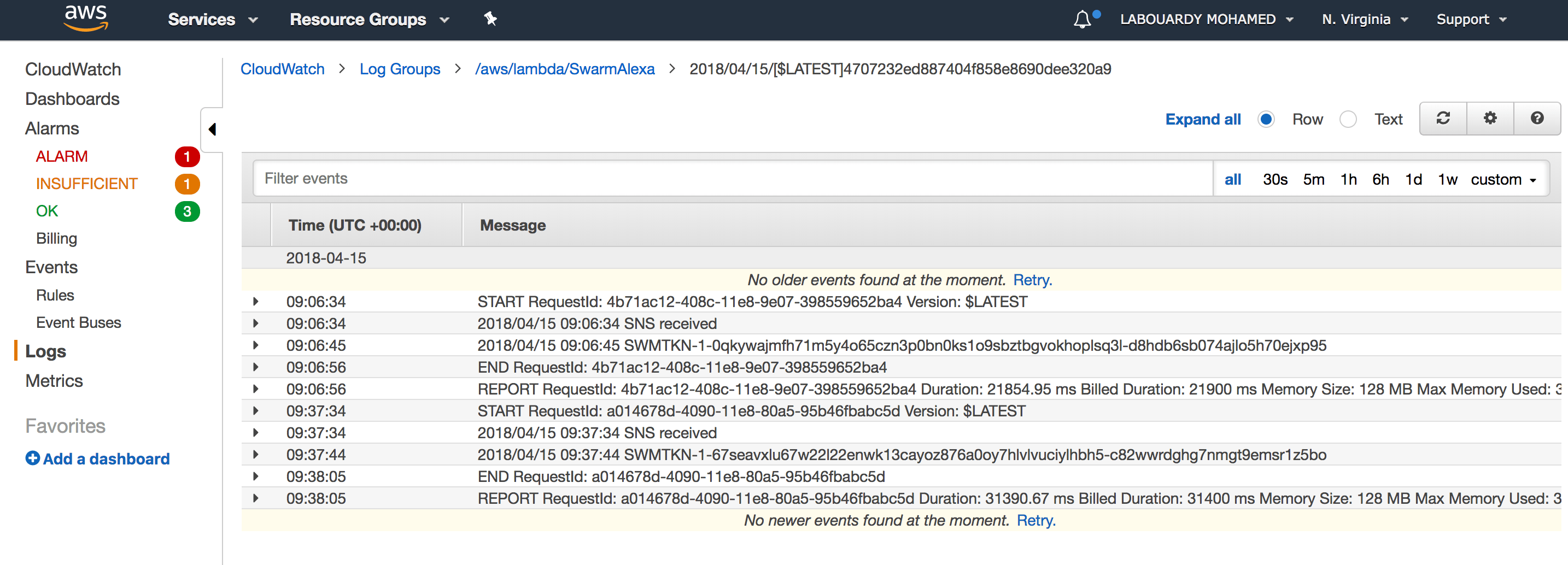
For debugging, the function will output the Swarm Token to CloudWatch:
Finally, it will update the DynamoDB item state from Pending to Done and delete the message from SQS.
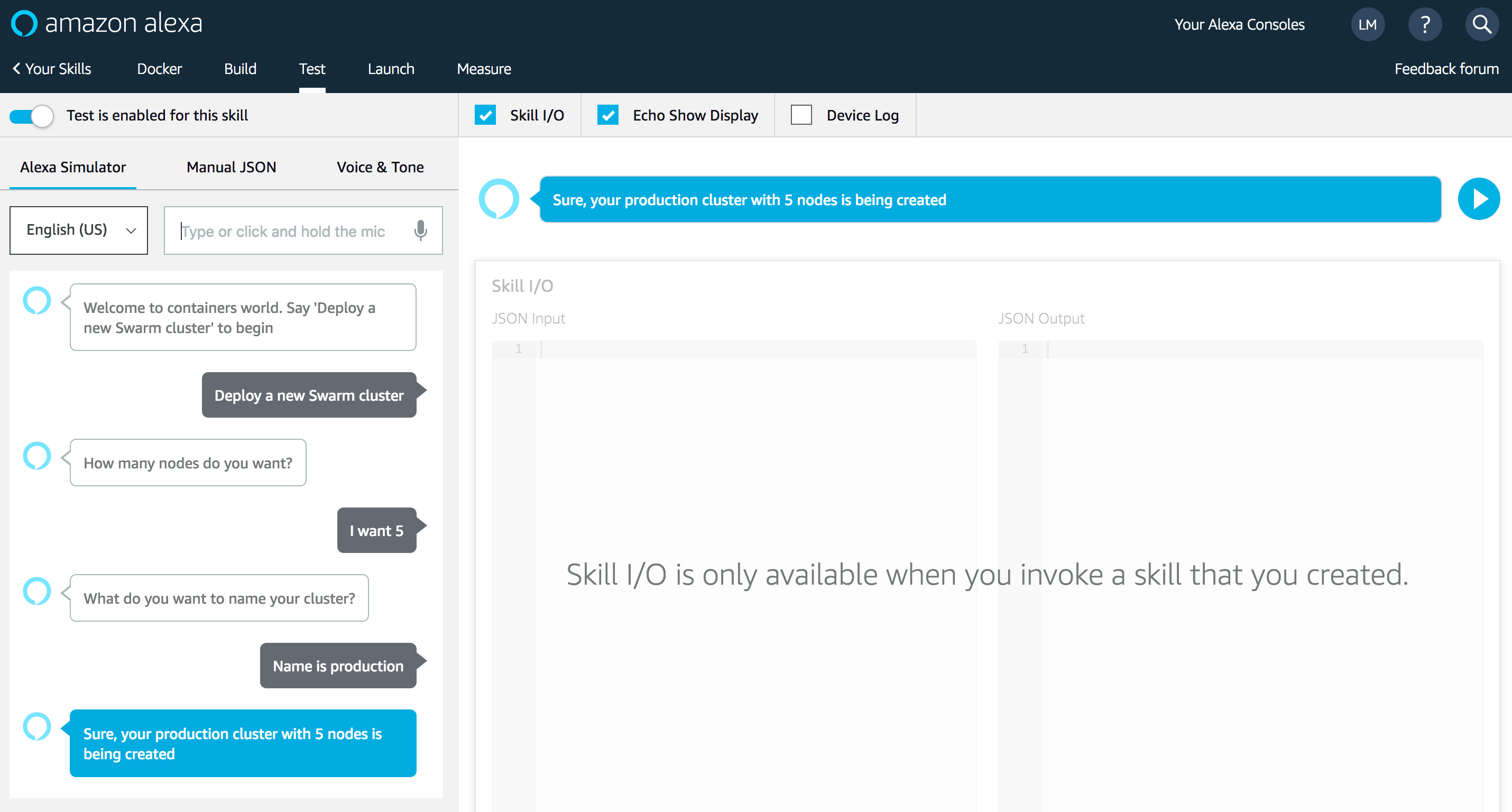
You can test your skill on your Amazon Echo, Echo Dot, or any Alexa device by saying, “Alexa, open Docker”
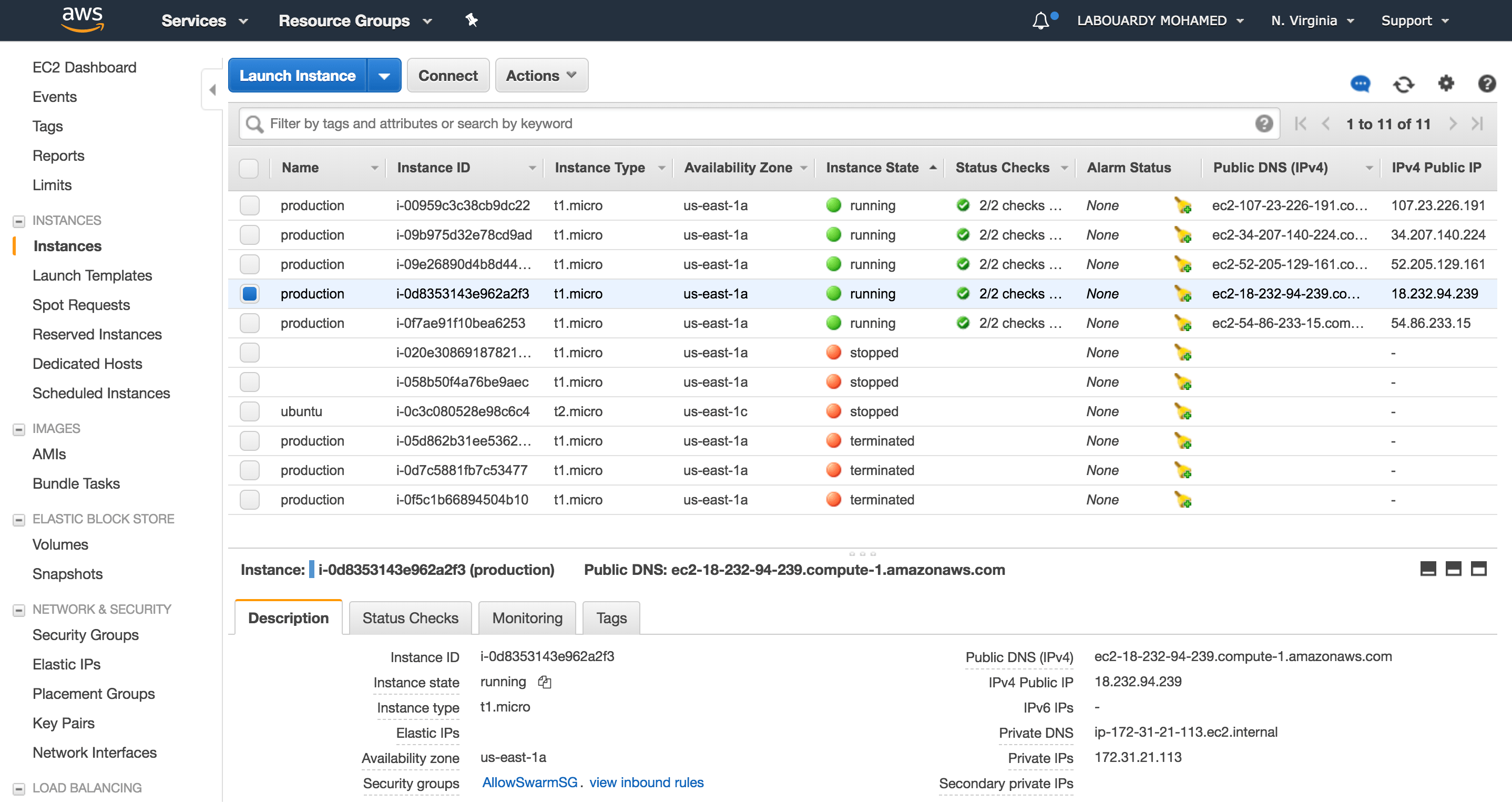
At the end of the workflow described above, a Swarm cluster will be created:
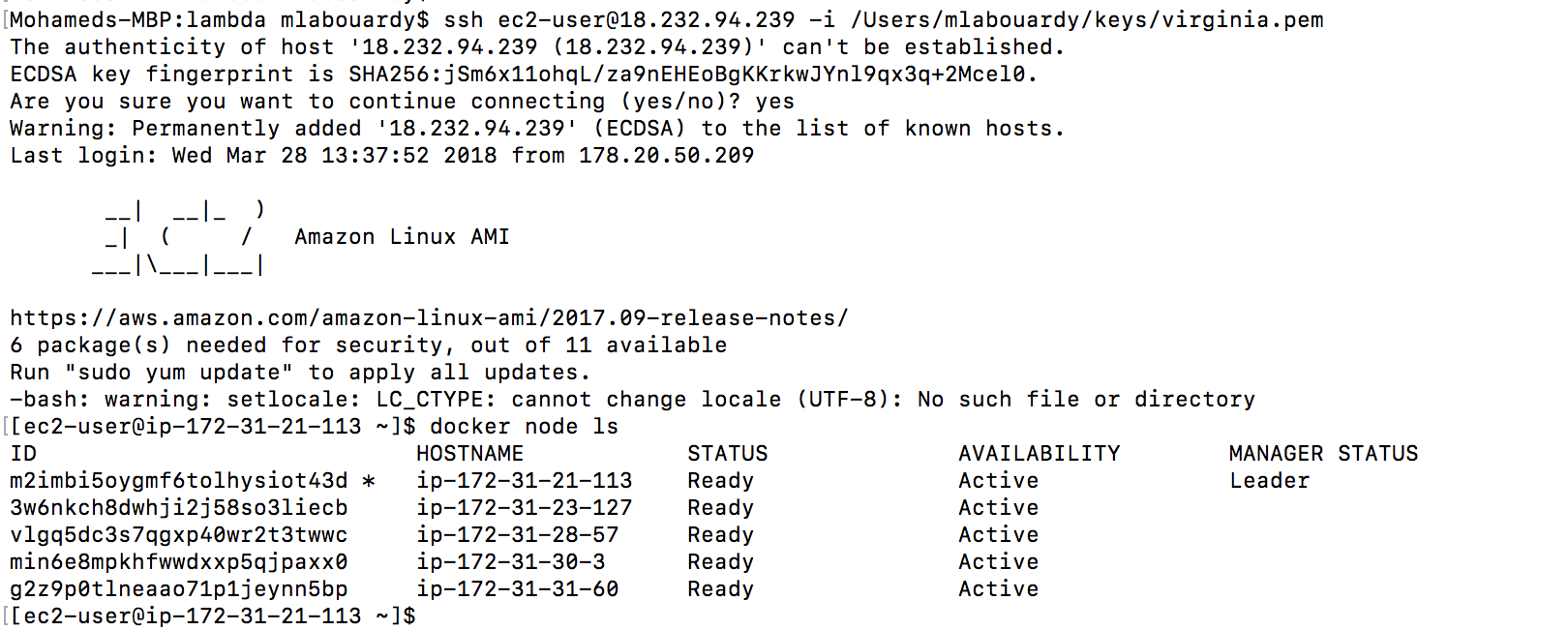
At this point you can see your Swarm status by firing the following command as shown below:
Improvements & Limitations:
Lambda execution timeout if the cluster size is huge. You can use a Master Lambda function to spawn child Lambda.
CloudWatch & SNS parts can be deleted if SQS is supported as Lambda event source (AWS PLEAAASE !). DynamoDB streams or Kinesis streams cannot be used to notify Lambda as I wanted to create some kind of delay for the instances to be fully created before setting up the Swarm cluster. (maybe Simple Workflow Service ?)
Inject SNS before SQS. SNS can add the message to SQS and trigger the Lambda function. We won’t need CloudWatch Alarm.
You can improve the Skill by adding new custom intents to deploy Docker containers on the cluster or ask Alexa to deploy the cluster on a VPC …
In-depth details about the skill can be found on my GitHub. Make sure to drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.
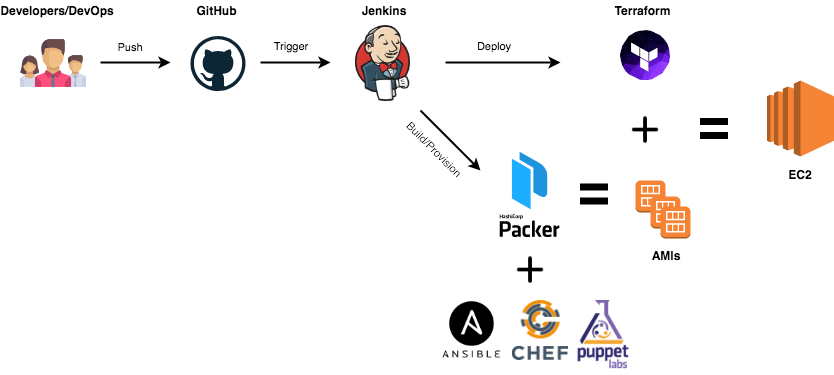
When dealing with Hybrid or multi-cloud environments, you would need to have an identical machine images for multiple platforms from a single source configuration. That’s were Packer comes into play.
To get started, find the appropriate package for your system and download Packer:
With Packer installed, let’s just dive right into it and bake our AMI with a preinstalled Docker Engine in order to build a Swarm or Kubernetes cluster and avoid cold-start of node machines.
Packer is template-driven, templates are written in JSON format:
variables: Custom variables that can be overriden during runtime by using the -var flag. In the above snippet, we’re specifying the AWS region.
builders: You can specify multiple builders depending on the target platforms (EC2, VMware, Google Cloud, Docker …).
provisioners: You can pass a shell script or use configuration managements tools like Ansible, Chef, Puppet or Salt to provision the AMI and install all required packages and softwares.
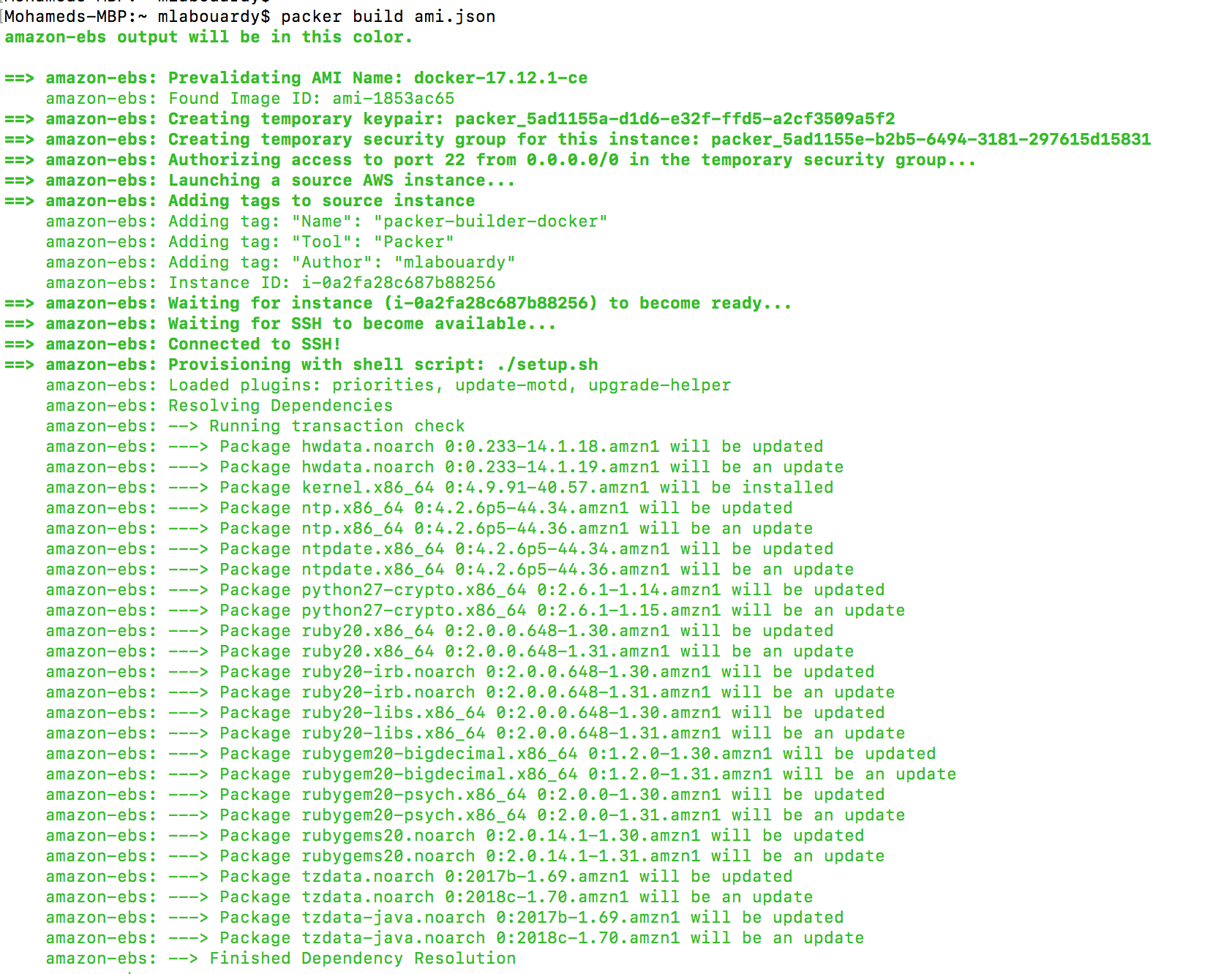
Packer will use an existing Amazon Linux Image “Gold Image” from the marketplace and install the latest Docker community edition using the following Bash script:
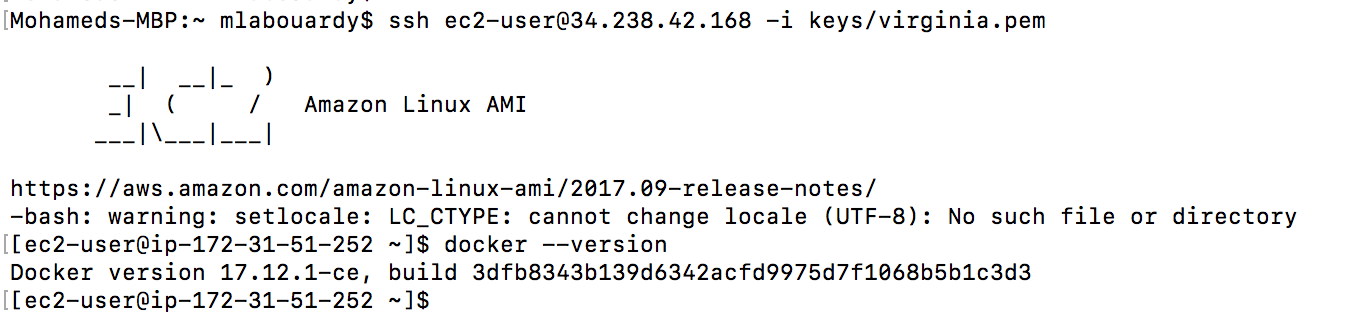
Then, connect to your instance via SSH and type the following command to verify Docker latest release is installed:
Simple right ? Well, you can go further and setup a CI/CD pipeline to build your AMIs on every push, recreate your EC2 instances with the new AMIs and rollback in case of failure.
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.
Being an AWS Certified can boost your career (increasing your salary, finding better job or getting a promotion) and make your expertise and skills relevant. Hence, there’s no better way to prepare for your AWS Certified Developer Associate exam than getting your hands dirty and build a Serverless Quiz game with Alexa Skill and AWS Lambda.
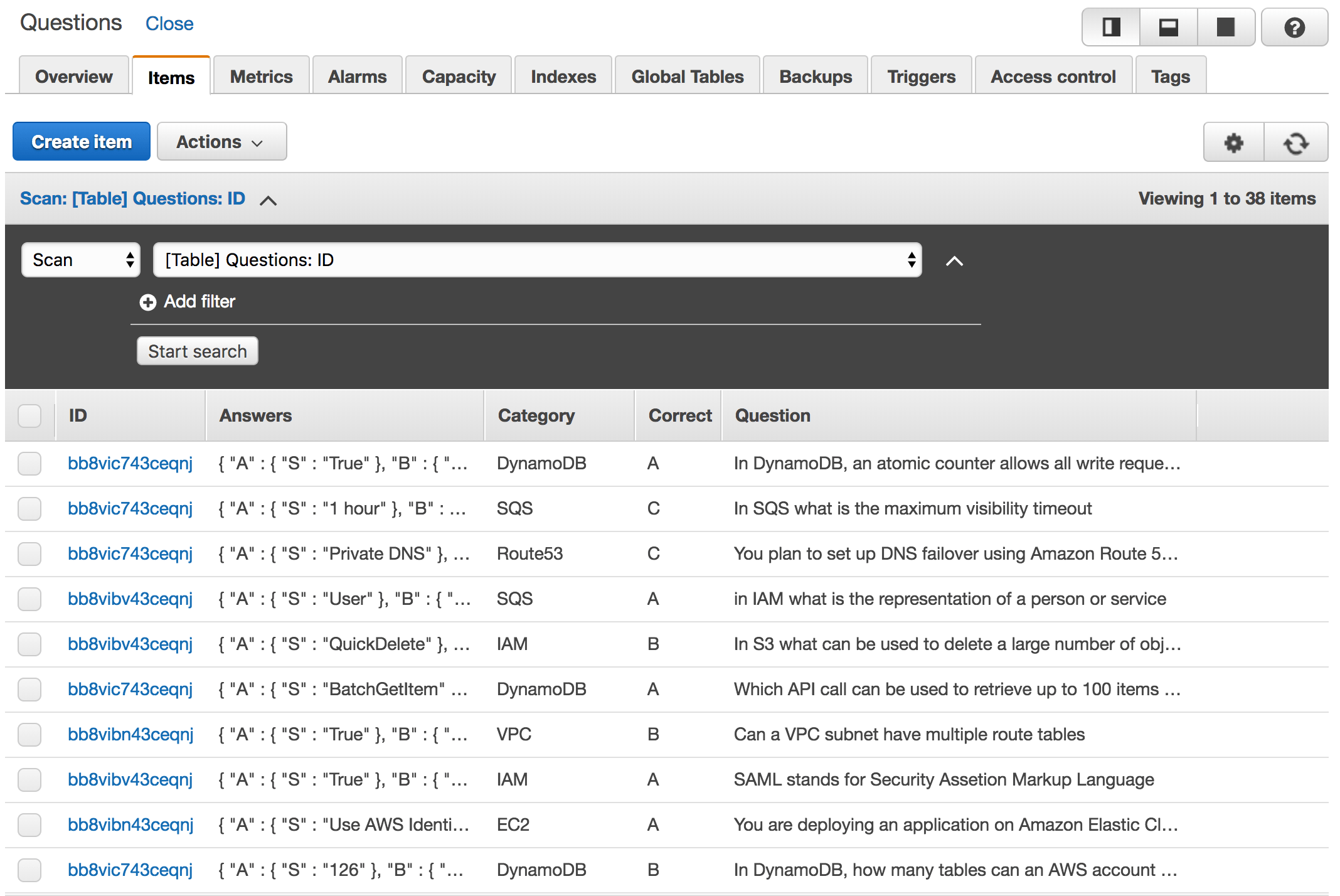
[ { "category" : "S3", "questions" : [ { "question": "In S3 what can be used to delete a large number of objects", "answers" : { "A" : "QuickDelete", "B" : "Multi-Object Delete", "C" : "Multi-S3 Delete", "D" : "There is no such option available" }, "correct" : "B" }, { "question": "S3 buckets can contain both encrypted and non-encrypted objects", "answers" : { "A" : "False", "B" : "True" }, "correct" : "B" } ] } ]
Run the main.go file by issuing the following command:
If you navigate to DynamoDB Dashboard, you should see that the list of questions has been successfully inserted:
2 – Alexa Skill
This is what ties it all together, by linking the phrases the user says to interact with the quiz to the intents.
For people who are not familiar with NLP. Alexa is based on an NLP Engine which is a system that analyses phrases (users messages) and returns an intent. Intents describe what a user want or want to do. It is the intention behind his message. Alexa can learn new intents by attributing examples of messages to an intent. Behind the scenes, the Engine will be able to predict the intent even if he had never seen it before.
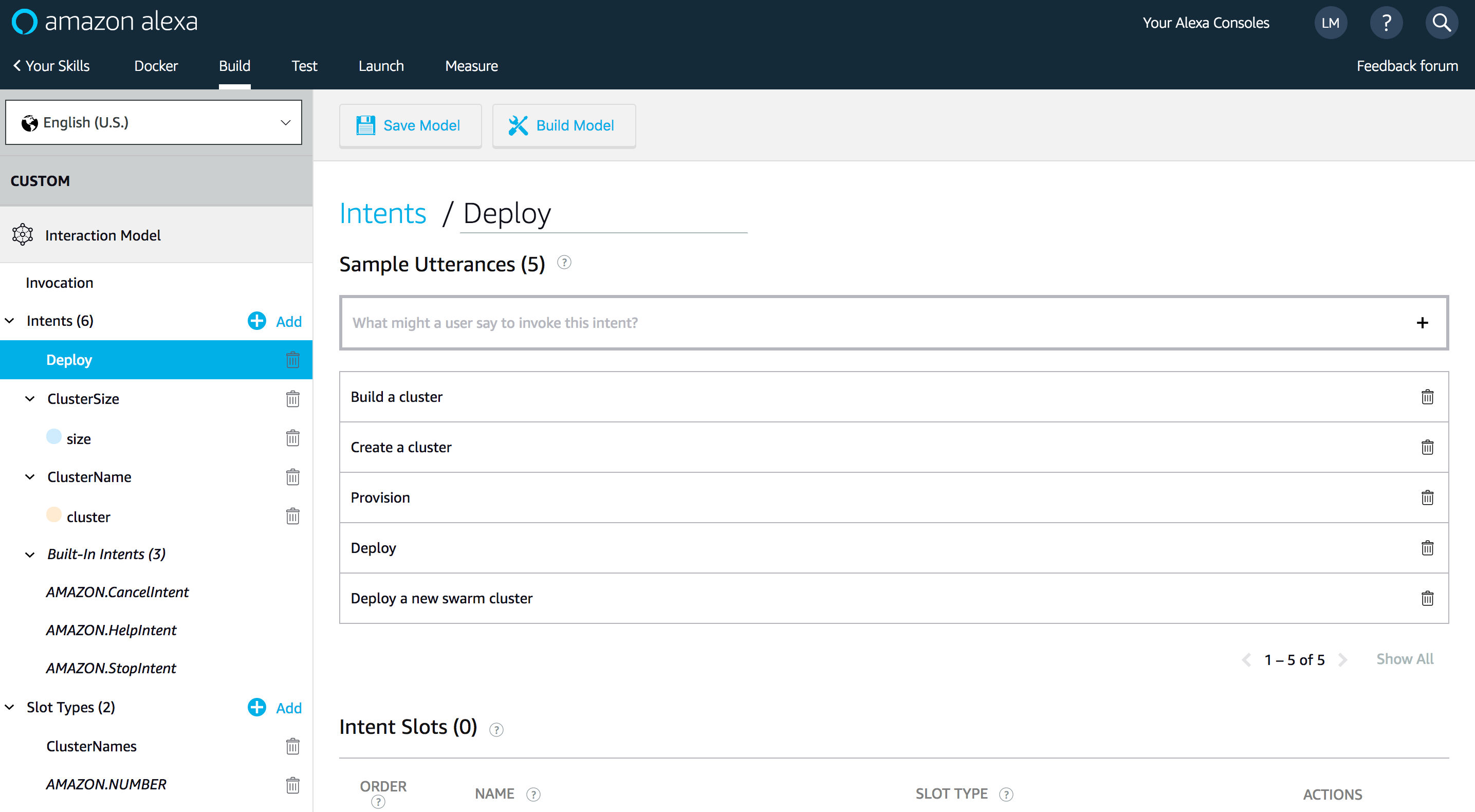
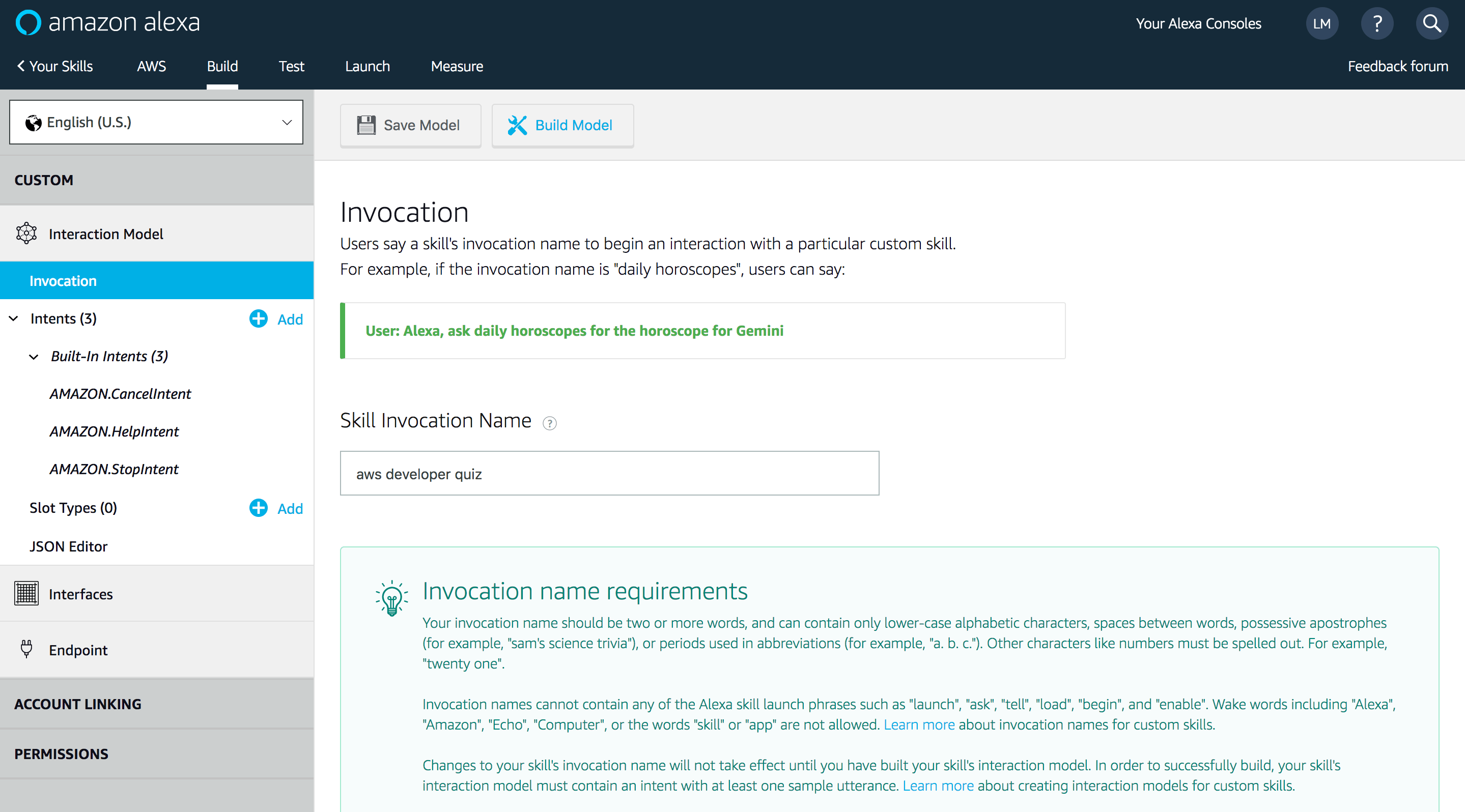
So, sign up to Amazon Developer Console, and create a new custom Alexa Skill. Set an invocation name as follows:
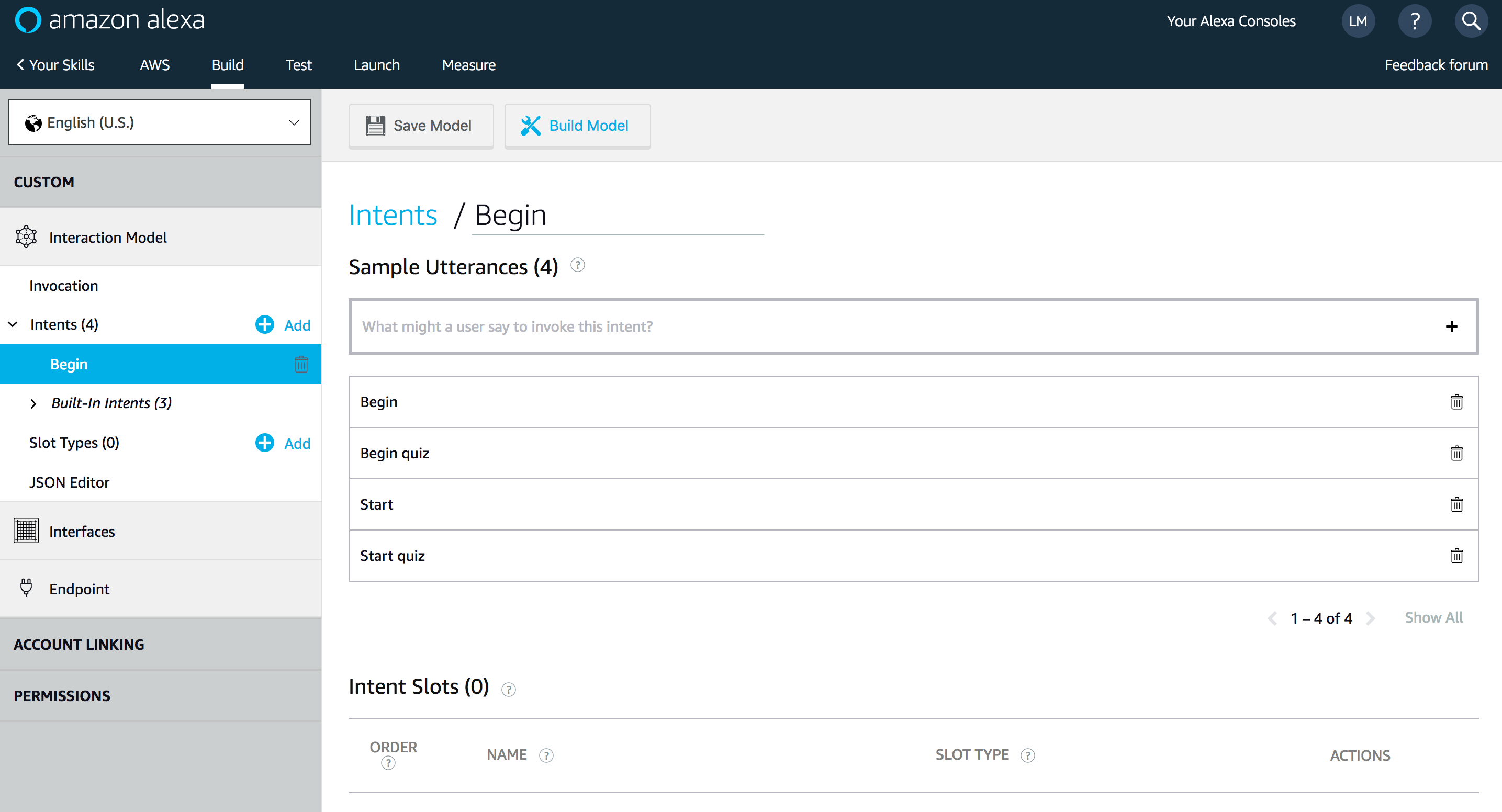
Create a new Intent for starting the Quiz:
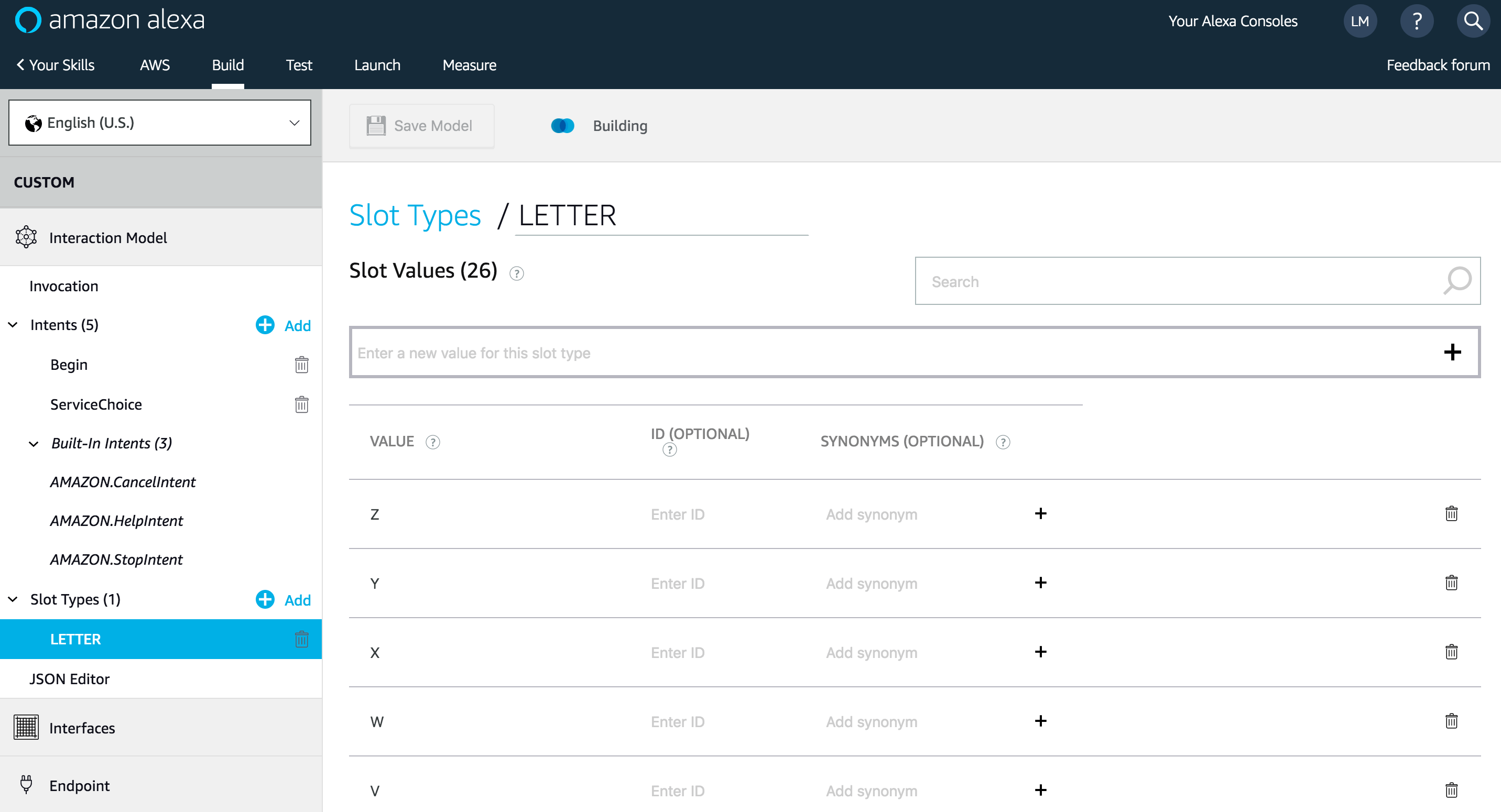
Add a new type “Slot” to store user choice:
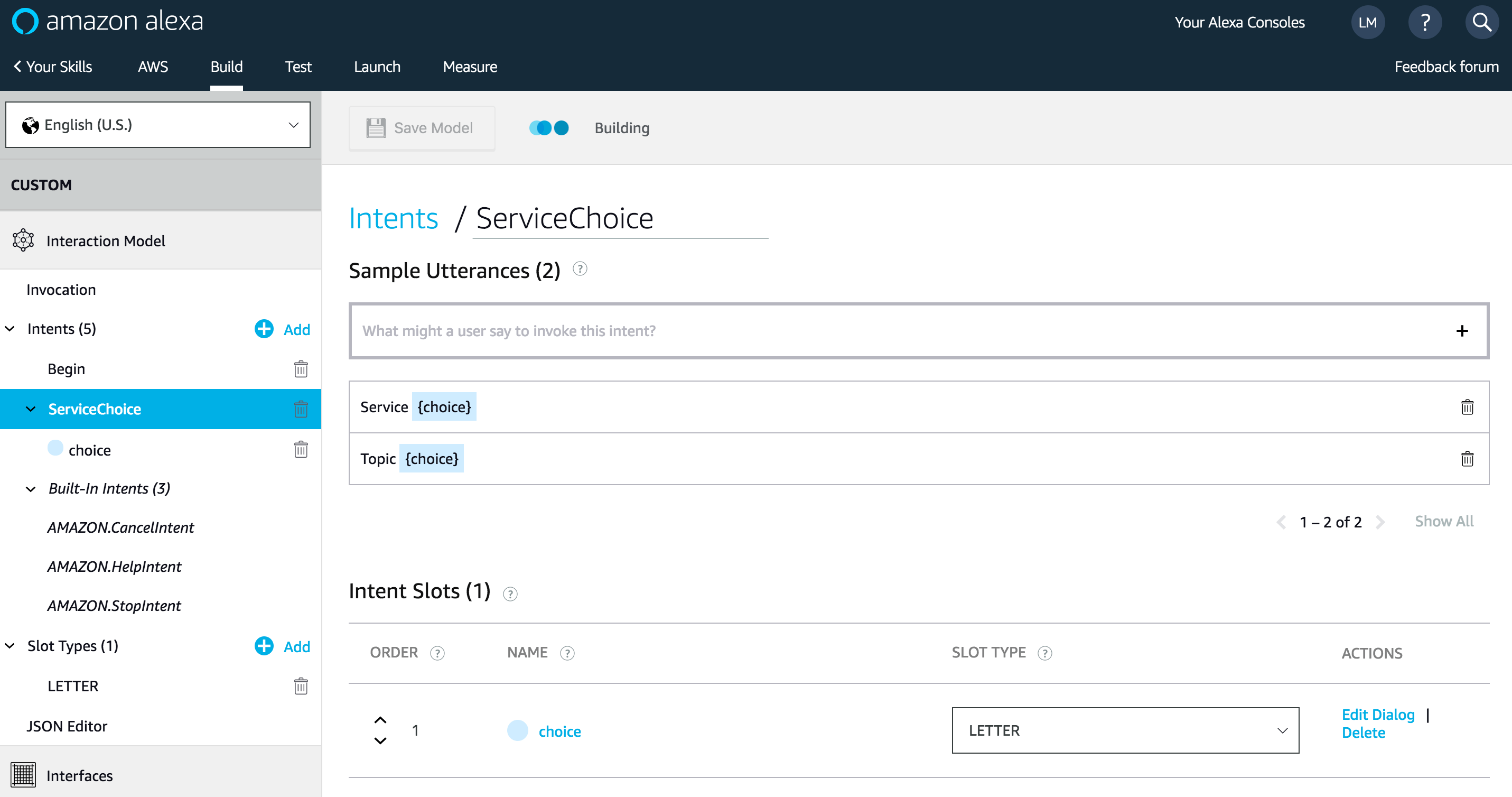
Then, create another intent for AWS service choice:
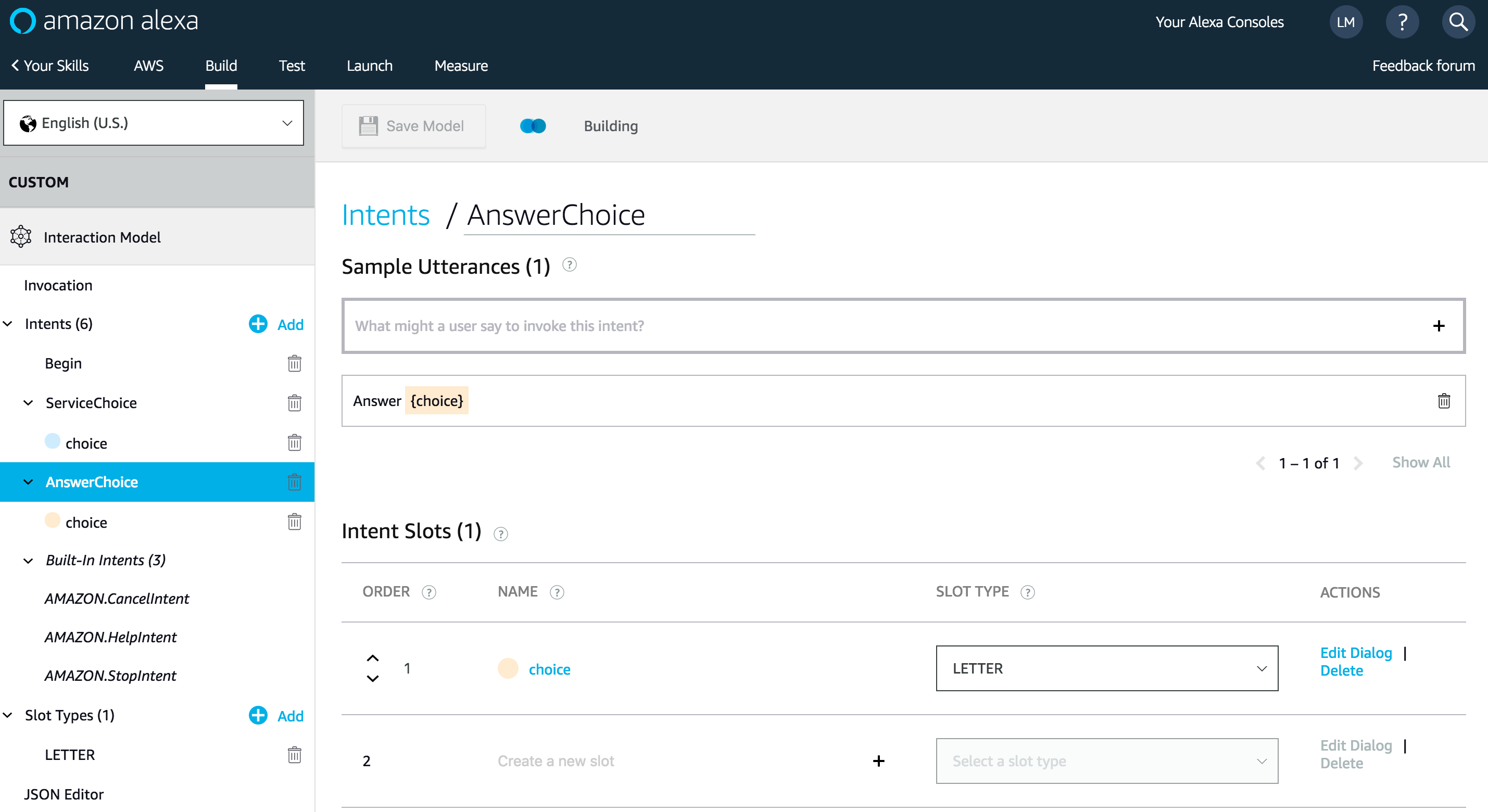
And for user’s answer choice:
Save your interaction model. Then, you’re ready to configure your Alexa Skill.
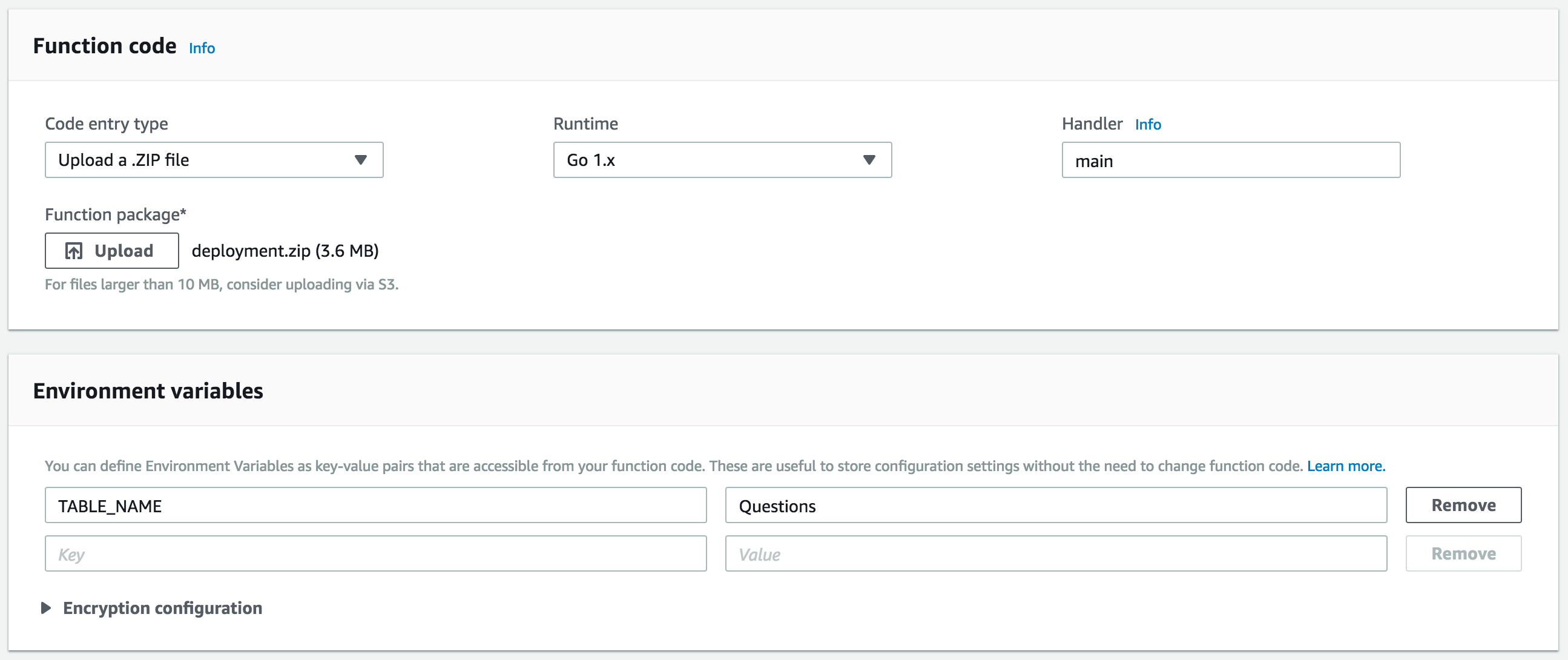
3 – Lambda Function
The Lambda handler function is self explanatory, it maps each intent to a code snippet. To keep track of the user’s score. We use Alexa sessionAttributes property of the JSON response. The session attributes will then be passed back to you with the next request JSON inside the session’s object. The list of questions is retrieved from DynamoDB using AWS SDK and SSML (Speech Synthesis Markup Language) is used to make Alexa speaks a sentence ending in a question mark as a question or add pause in the speech:
funcHandleRequest(ctx context.Context, r AlexaRequest)(AlexaResponse, error) { resp := CreateResponse()
switch r.Request.Intent.Name { case"Begin": resp.Say(`<speak> Choose the AWS service you want to be tested on <break time="1s"/> A <break time="1s"/> EC2 <break time="1s"/> B <break time="1s"/> VPC <break time="1s"/> C <break time="1s"/> DynamoDB <break time="1s"/> D <break time="1s"/> S3 <break time="1s"/> E <break time="1s"/> SQS </speak>`, false, "SSML") case"ServiceChoice": number := strings.TrimSuffix(r.Request.Intent.Slots["choice"].Value, ".")
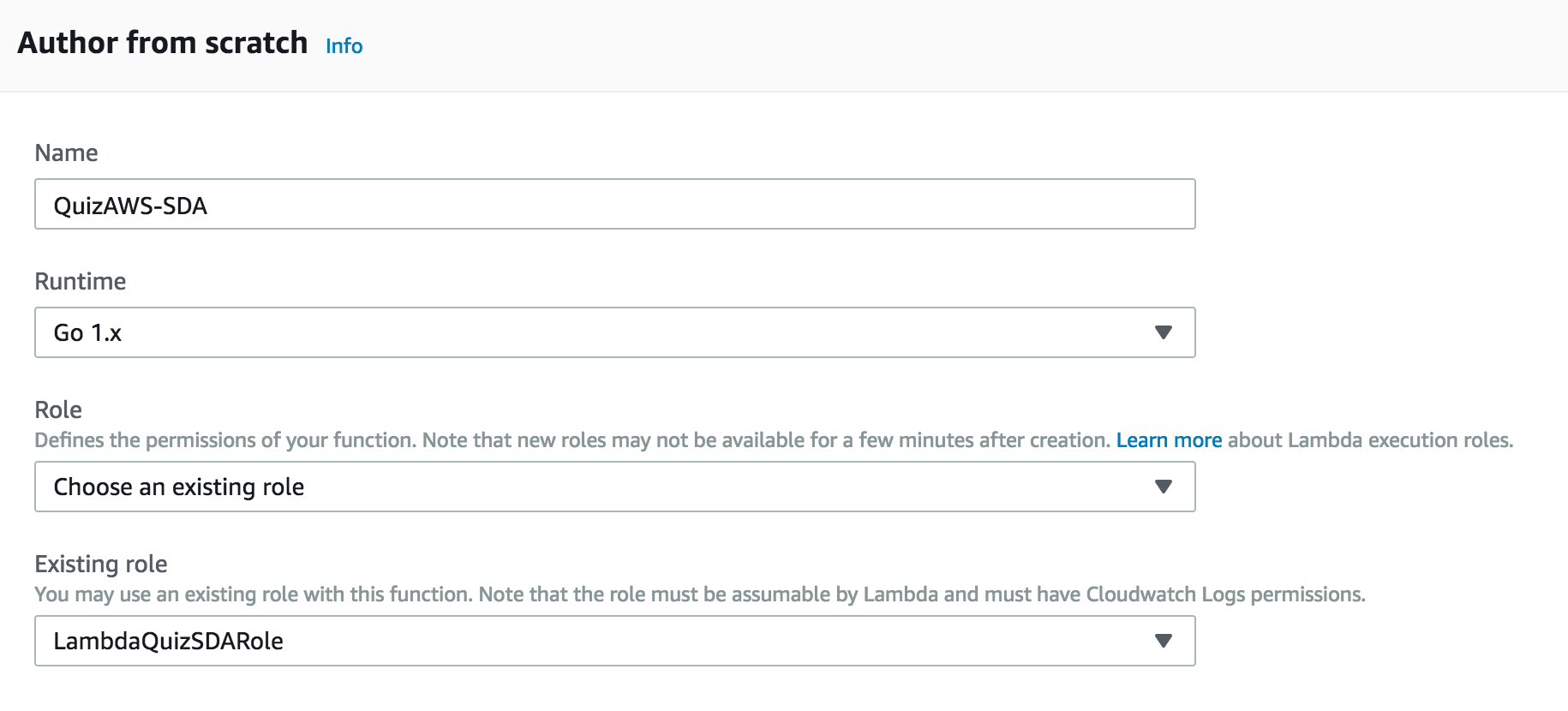
Generate the deployment package, and upload it to the Lambda Console and set the TABLE_NAME environment variable to the table name:
4 – Testing
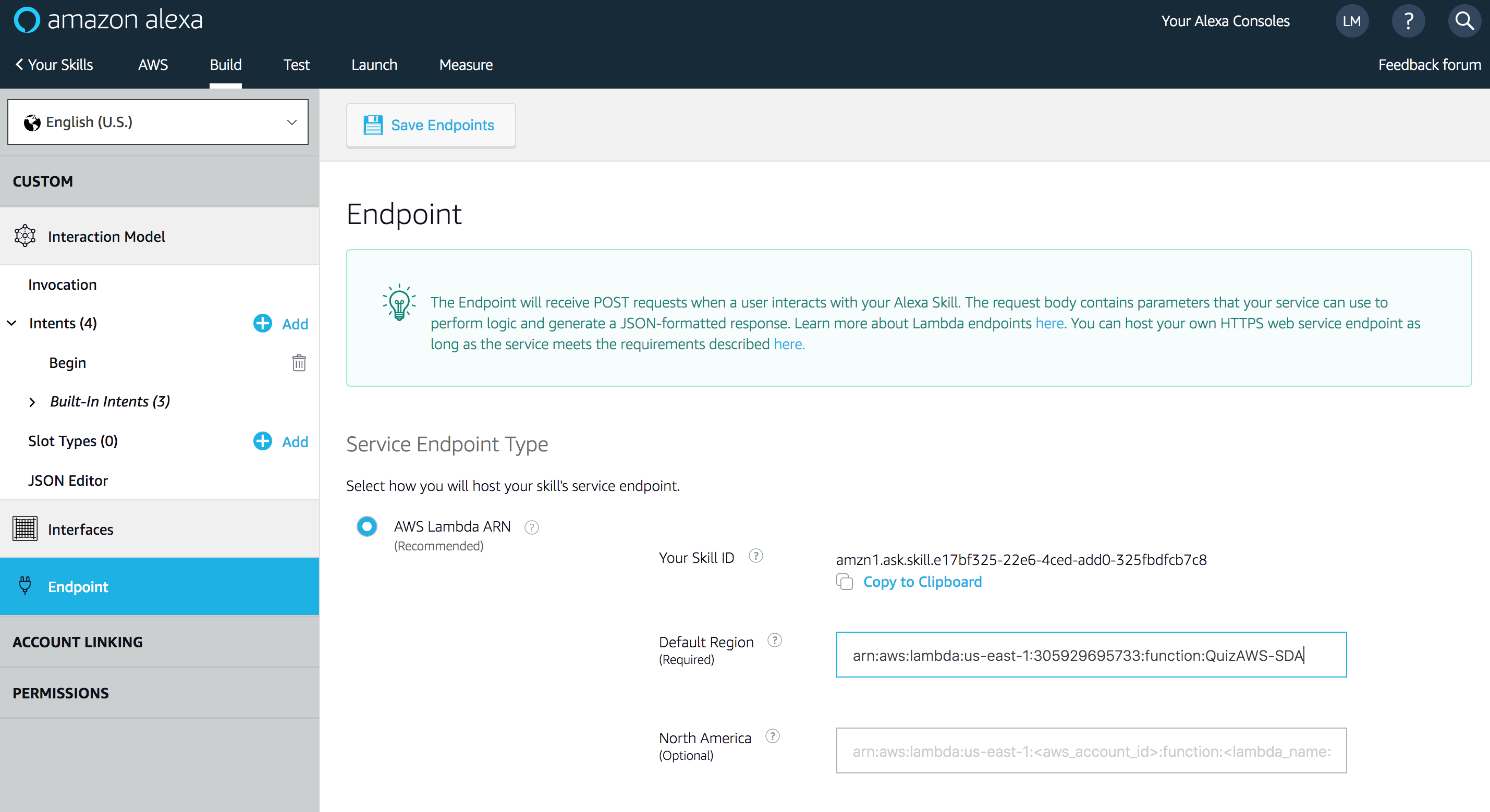
Now that you have created the function and put its code in place, it’s time to specify how it gets called. We’ll do this by linking the Lambda ARN to Alexa Skill:
Once the information is in place, click Save Endpoints. You’re ready to start testing your new Alexa Skill !
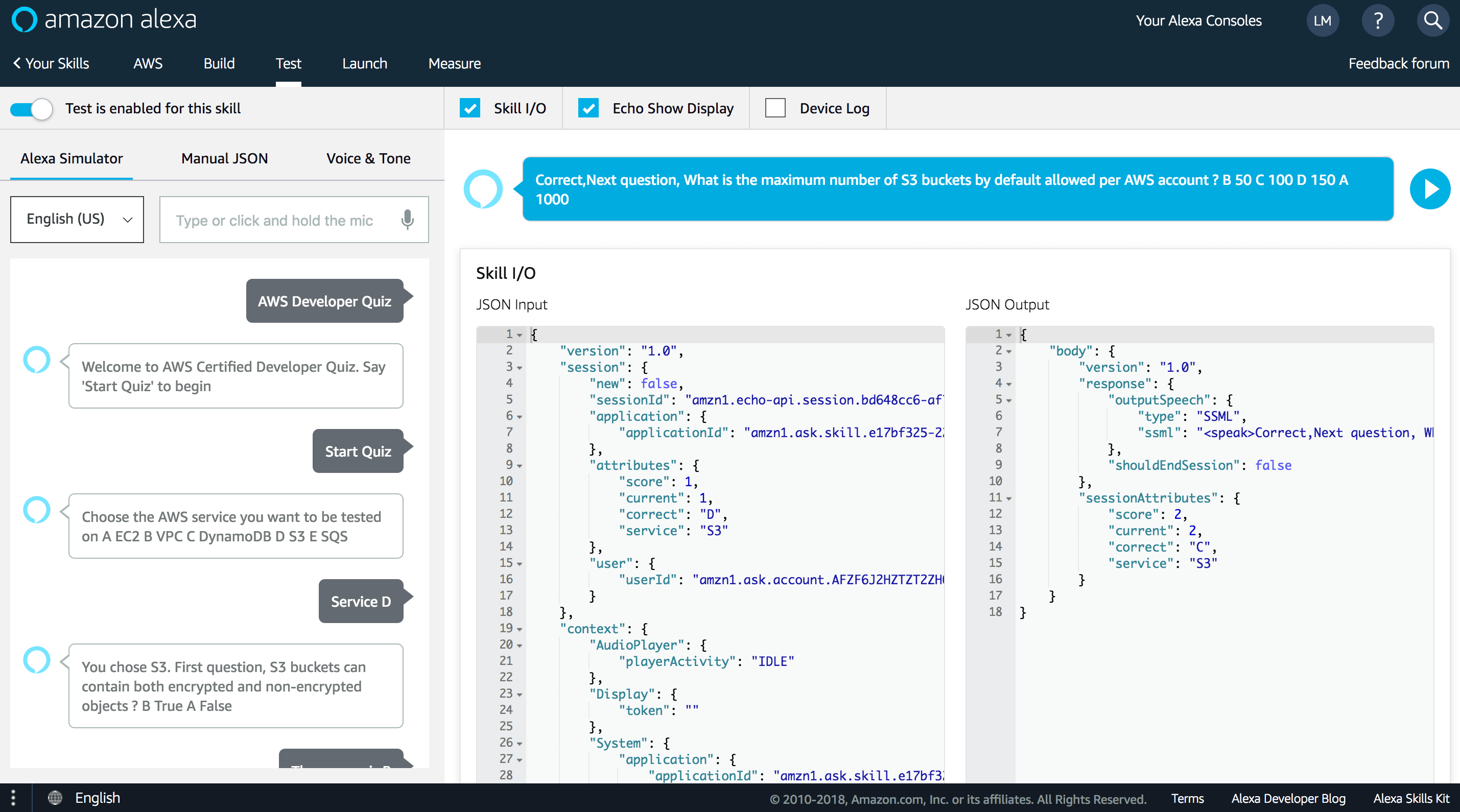
To test, you need to login to Alexa Developer Console, and enable the “Test” switch on your skill from the “Test” Tab:
Or use an Alexa enabled device like Amazon Echo, by saying “Alexa, Open AWS Developer Quiz” :
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.
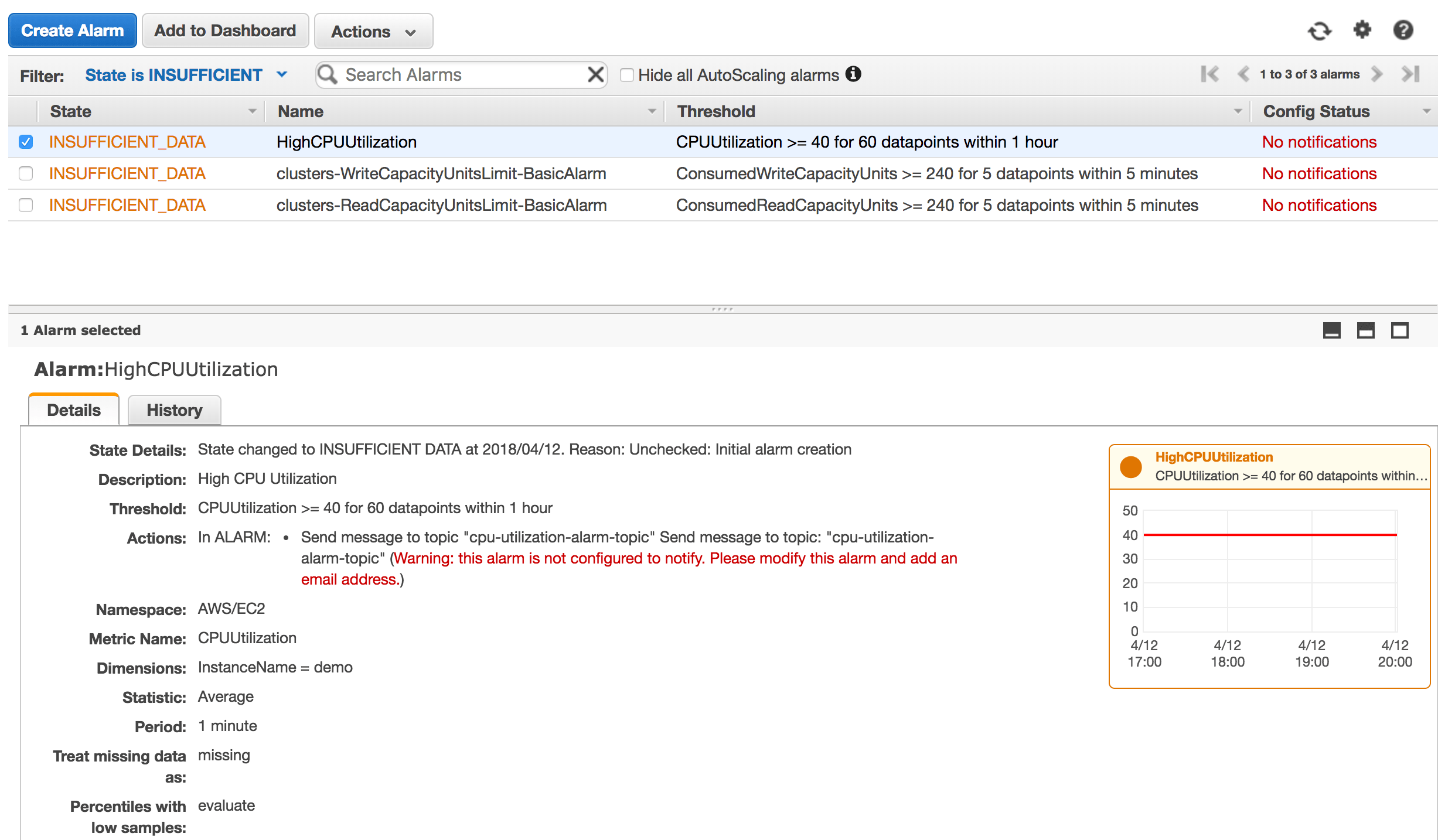
ChatOps has emerged as one of the most effective techniques to implement DevOps. Hence, it will be great to receive notifications and infrastructure alerts into collaboration messaging platforms like Slack & HipChat.
AWS CloudWatch Alarms and SNS are a great mix to build a real-time notification system as SNS supports multiple endpoints (Email, HTTP, Lambda, SQS). Unfortunately SNS doesn’t support out of the box sending notifications to tools like Slack.
CloudWatch will trigger an alarm to send a message to an SNS topic if the monitoring data gets out of range. A Lambda function will be invoked in response of SNS receiving the message and will call the Slack API to post a message to Slack channel.
To get started, create an EC2 instance using the AWS Management Console or the AWS CLI:
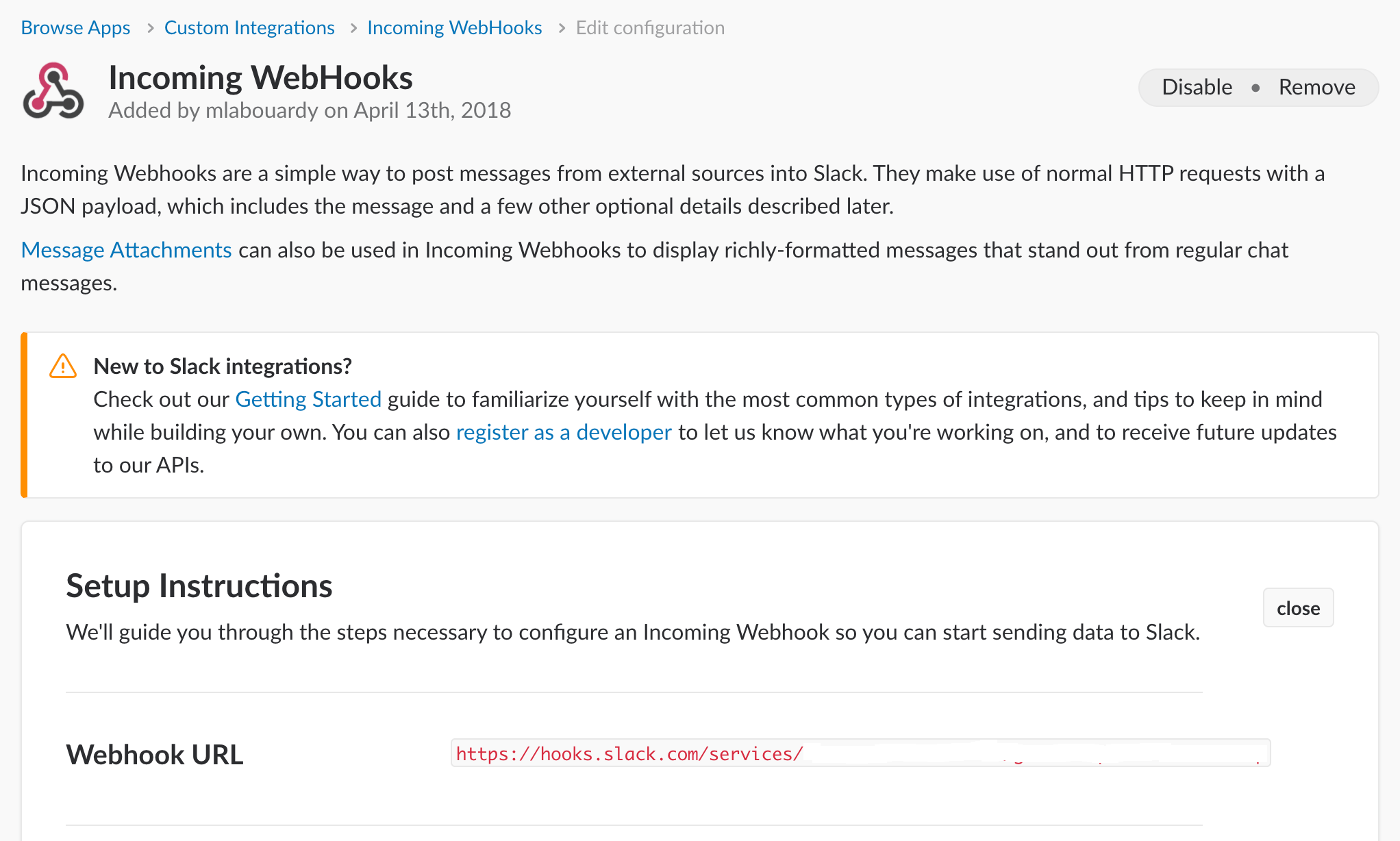
To be able to post messages to slack channel, we need to create a Slack Incoming WebHook. Start by setting up an incoming webhook integration in your Slack workspace:
Note down the returned WebHook URL for upcoming part.
The Lambda handler function is written in Go, it takes as an argument the SNS message. Then, it parses it and queries the Slack API to post a message to the Slack channel configured in the previous section:
Are you tired of maintaining your CMS (WordPress, Drupal, etc) ? Paying expensive hosting fees? Fixing security issues everyday ?
I discovered not long ago a new blogging framework called Hexo which let you publish Markdown documents in the form of blog post. So as always I got my hands dirty and wrote this post to show you how to build a production-ready blog with Hexo and use the AWS S3 to make your blog Serverless and pay only per usage. Along the way, I will show you how to automate the deployment of new posts by setting up a CI/CD pipeline
To get started, Hexo requires Node.JS & Git to be installed. Once all requirements are installed, issue the following command to install Hexo CLI:
1
npm install -g hexo-cli
Next, create a new empty project:
1
hexo init slowcoder.com
Modify blog global settings in _config.yml file:
1 2 3 4 5 6 7 8
# Site title: SlowCoder subtitle: DevOps News and Tutorials description: DevOps, Cloud, Serverless, Containers news and tutorials for everyone keywords: programming,devops,cloud,go,mobile,serverless,docker author: Mohamed Labouardy language: en timezone: Europe/Paris
Start a local server with “hexo server“. By default, this is at http://localhost:4000. You’ll see Hexo’s pre-defined “Hello World” test post:
If you want to change the default theme, you just need to go here and find a new one you prefer.
In order to automate the process of deployment of the blog to S3 each time a new article is been published. We will setup a CI/CD pipeline using CircleCI.
Sign in to CircleCI using your GitHub account, then add the circle.yml file to your project:
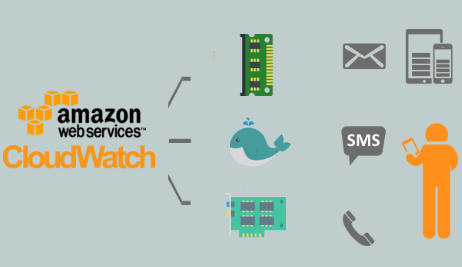
AWS Autoscaling Groups can only scale in response to metrics in CloudWatch and most of the default metrics are not sufficient for predictive scaling. That’s why you need to publish your custom metrics to CloudWatch.
I was surfing the internet as usual, and I couldn’t find any post talking about how to publish custom metrics to AWS CloudWatch, and because I’m a Gopher, I got my hand dirty and I wrote my own script in Go.
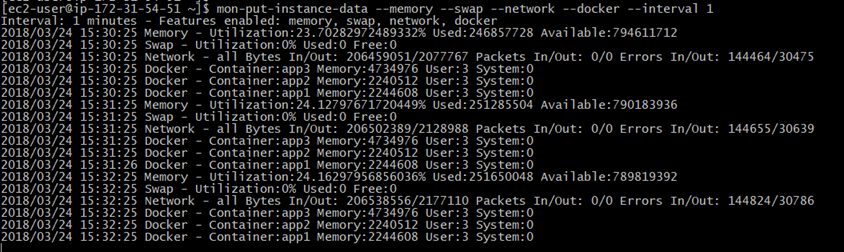
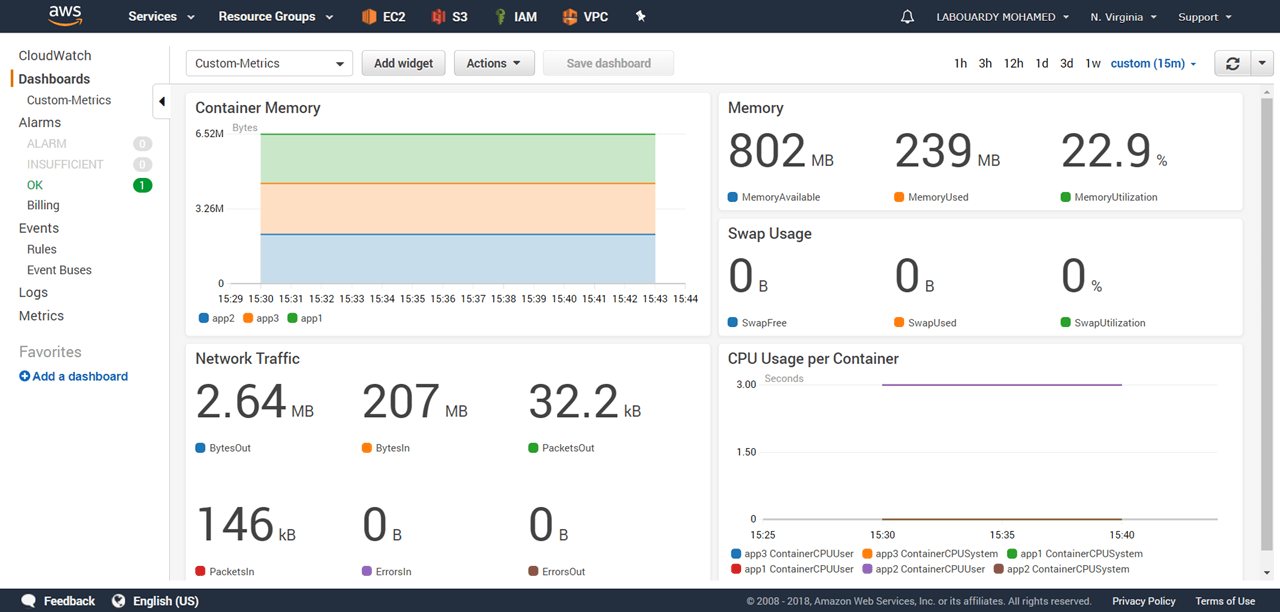
You can publish your own metrics to CloudWatch using the AWS Go SDK:
What if I’m not a Gopher ? well, don’t freak out, I built a simple CLI which doesn’t require any Go knowledge or dependencies to be installed (AWS CloudWatch Monitoring Scripts requires Perl dependencies) and moreover it’s cross-platform.
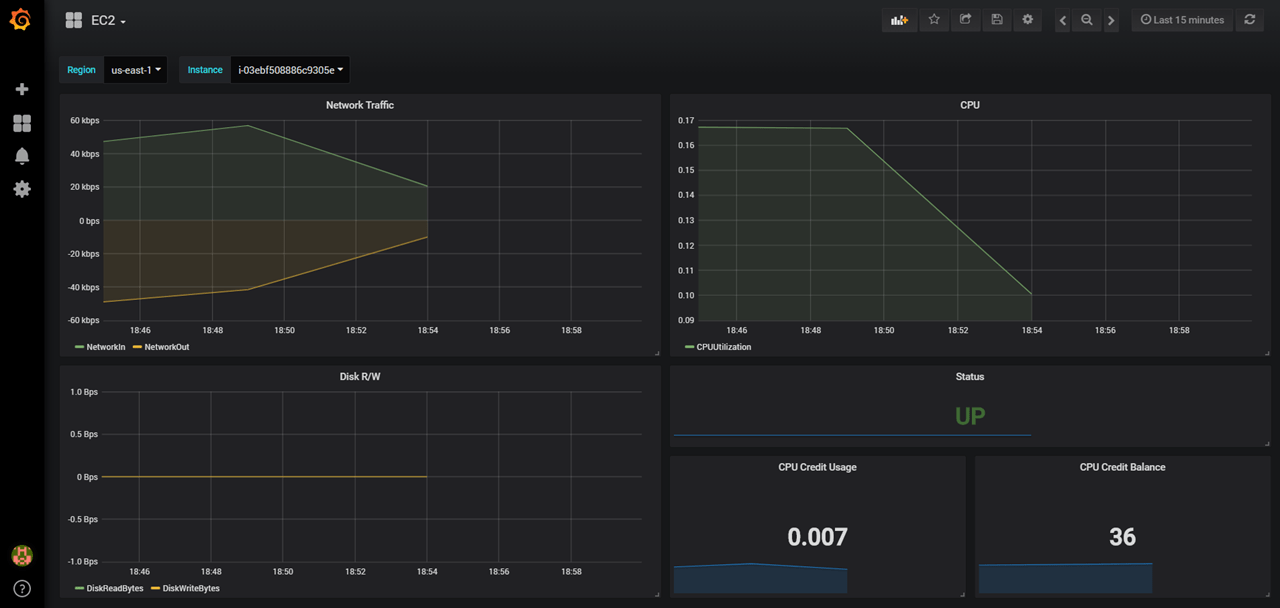
Hybrid cloud is the new reality. Therefore, you will need a single tool, general purpose dashboard and graph composer for your global infrastructure. That’s where Grafana comes into play. Due to it’s pluggable architecture, you have access to many widgets and plugins to create interactive & user-friendly dashboards. In this post, I will walk you through on how to create dashboards in Grafana to monitor in real-time your EC2 instances based on metrics collected in AWS CloudWatch.
To get started, create an IAM role with the following IAM policy:
On the security group section, allow inbound traffic on port 3000 (Grafana Dashboard).
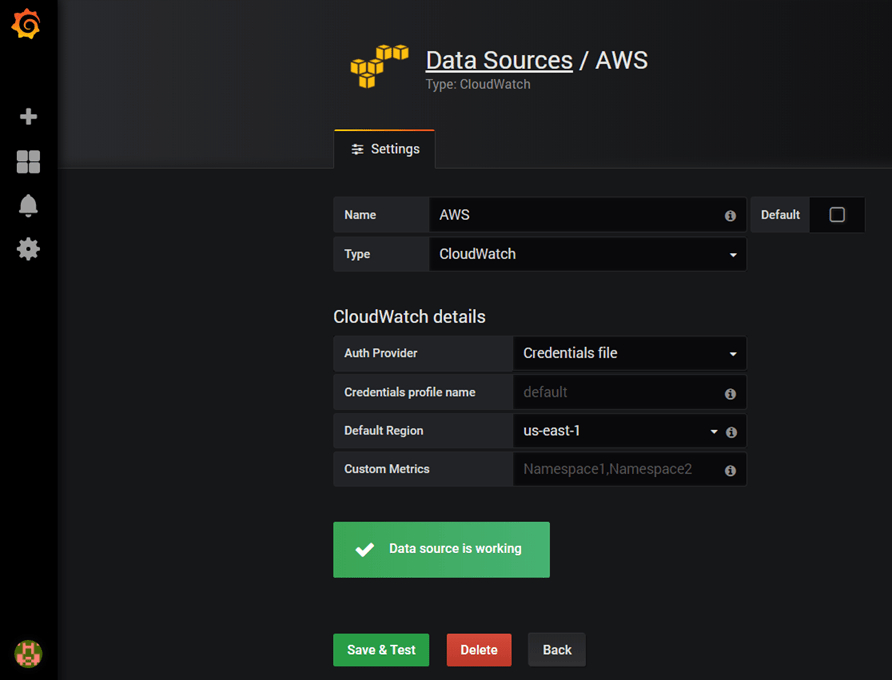
Once created, point your browser to the http://instance_dns_name:3000, you should see Grafana Login page (default credentials: admin/admin) :
Grafana ships with built in support for CloudWatch, so add a new data source:
Note: In case you are using an IAM Role (recommended), keep the other fields empty as above, otherwise, create a new file at ~/.aws/credentials with your own AWS Access Key & Secret key.
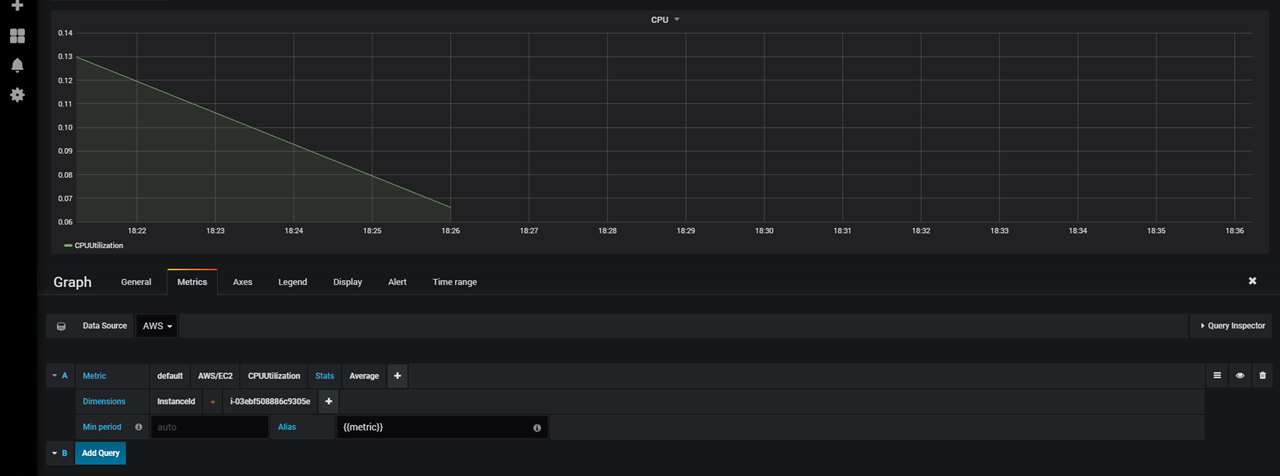
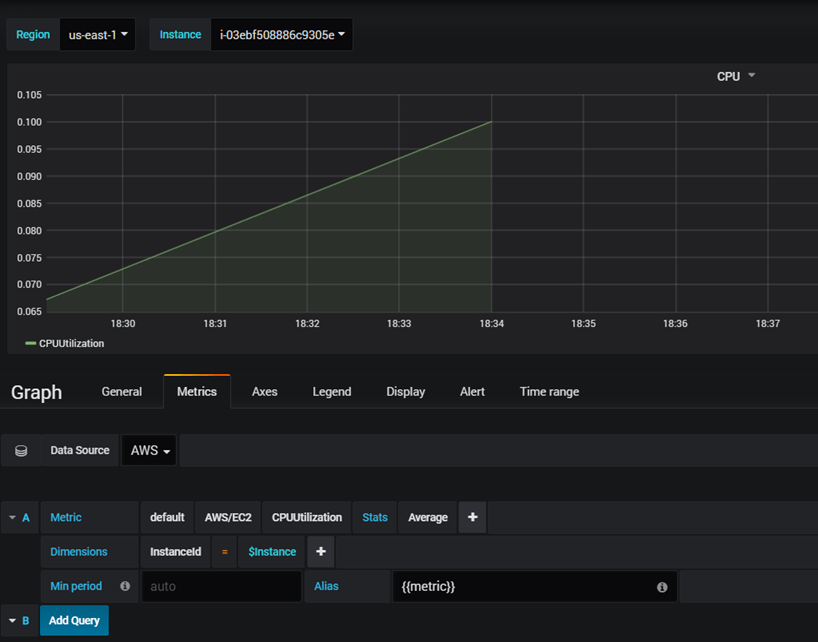
Create a new dashboard, and add new graph to the panel, select AWS/EC2 as namespace, CPUUtilization as metric, and the instance id of the instance you want to monitor in the dimension field:
That’s great !
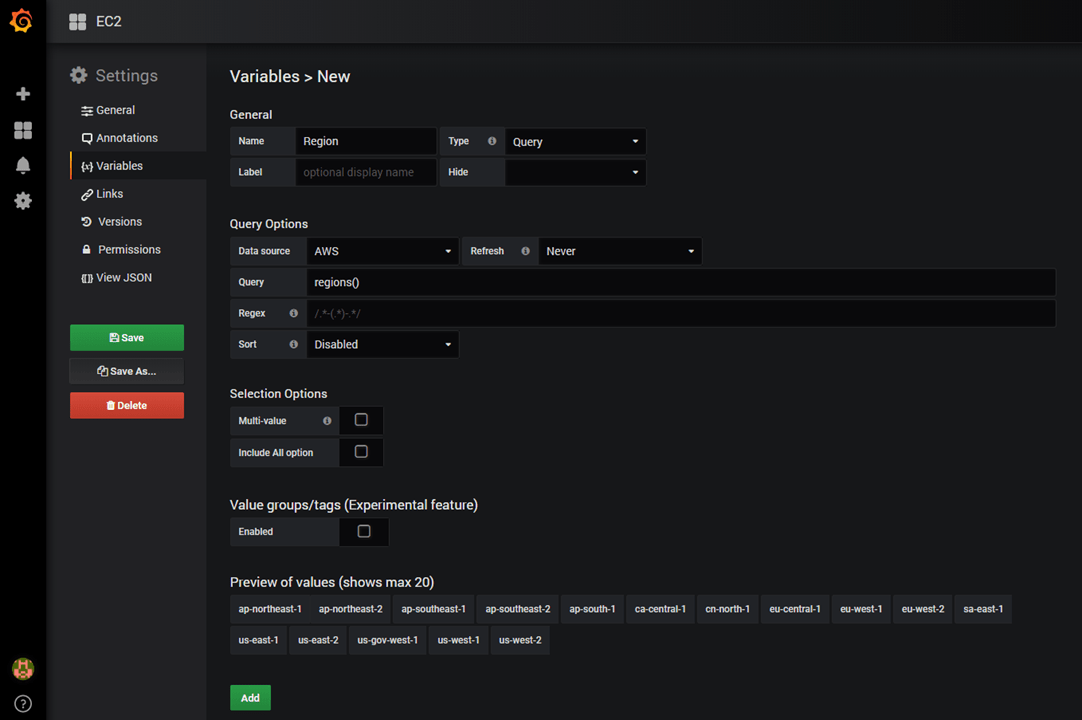
Well, instead of hard-coding the InstanceId in the query, we can use a feature in Grafana called “Query Variables“. Create a new variable to hold list of AWS supported regions :
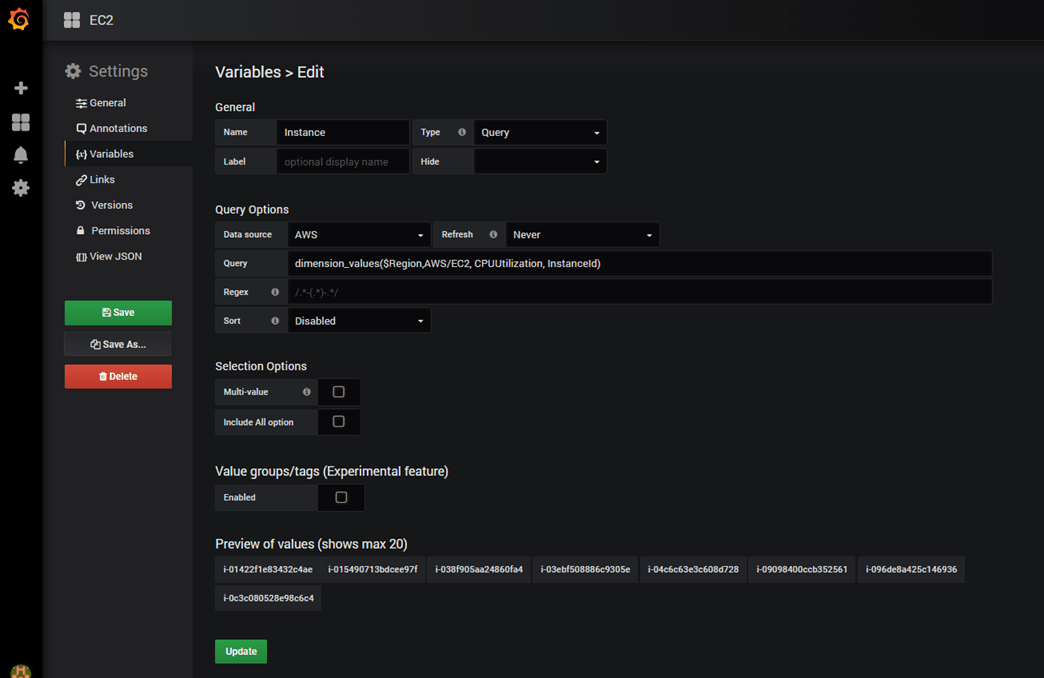
And, create a second variable to store list of instances ids per selected AWS region:
Now, go back to your graph and update the query as below:
In order to build HA & Resilient applications in AWS, you need to assume that everything will fail. Therefore, you always design and deploy your application in multiple AZ & regions. So you end up with many unused AWS resources (Snapshots, ELB, EC2, Elastic IP, etc) that could cost you a fortune.
One pillar of AWS Well-Architected Framework is Cost optimization. That’s why you need to have a global overview of your AWS Infrastructure. Fortunately, AWS offers many fully-managed services like CloudWatch, CloudTrail, Trusted Advisor & AWS Config to help you achieve that. But, they require a deep understanding of AWS Platform and they are not straighforward.
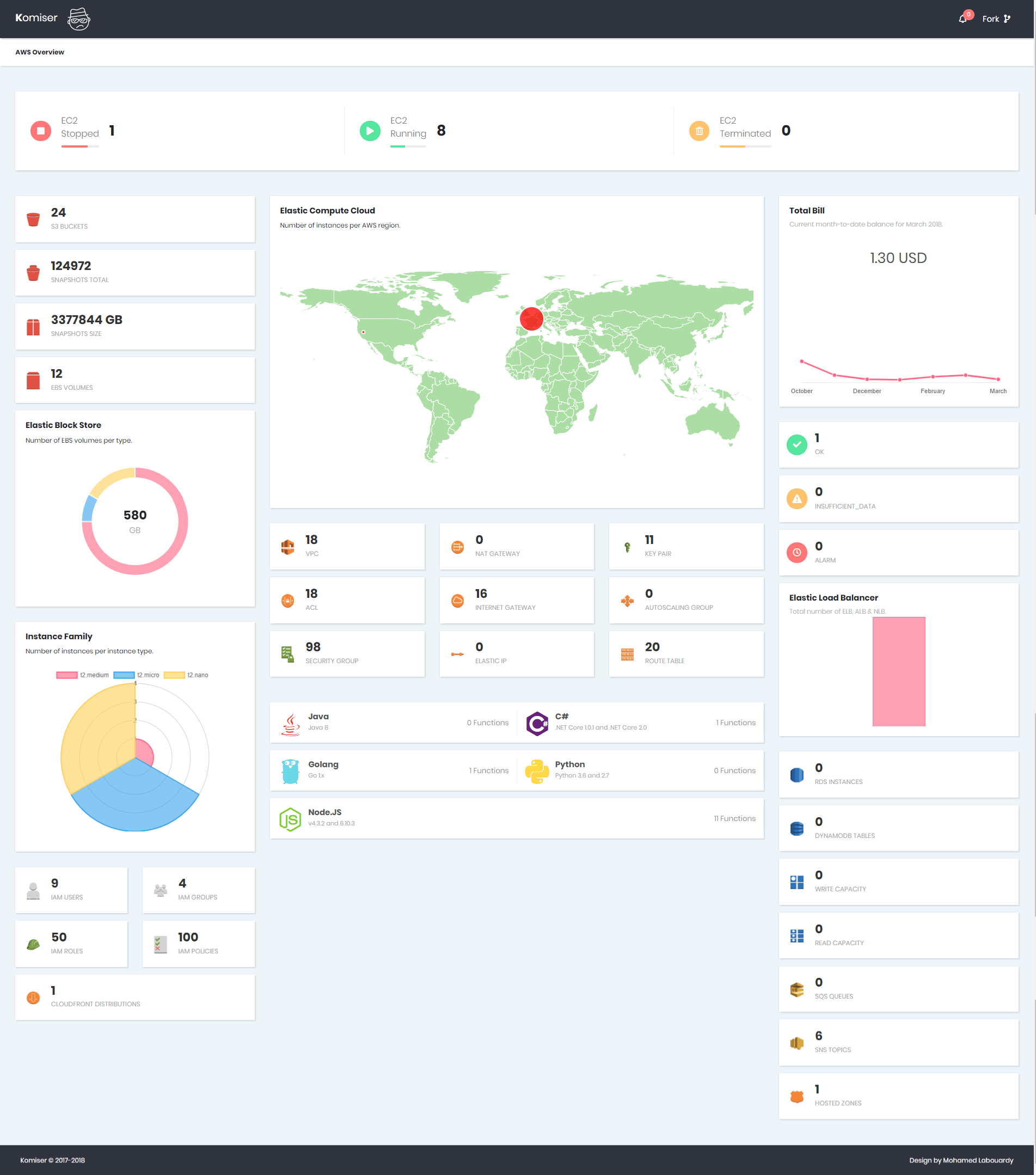
That’s why I came up with Komiser a tool that simplifies the process by querying the AWS API to fetch information about almost all critical services of AWS like EC2, RDS, ELB, S3, Lambda … in real-time in a single Dashboard.
Note: To prevent excedding AWS API rate limit for requests, the response is cached in in-memory cache by default for 30 minutes.
Komiser supported AWS Services:
Compute:
Running/Stopped/Terminated EC2 instances
Current EC2 instances per region
EC2 instances per family type
Lambda Functions per runtime environment
Disassociated Elastic IP addresses
Total number of Key Pairs
Total number of Auto Scaling Groups
Network & Content Delivery:
Total number of VPCs
Total number of Network Access Control Lists
Total number of Security Groups
Total number of Route Tables
Total number of Internet Gateways
Total number of Nat Gateways
Elastic Load Balancers per family type (ELB, ALB, NLB)
Management Tools:
CloudWatch Alarms State
Billing Report (Up to 6 months)
Database:
DynamoDB Tables
DynamoDB Provisionned Throughput
RDS DB instances
Messaging:
SQS Queues
SNS Topics
Storage:
S3 Buckets
EBS Volumes
EBS Snapshots
Security Identity & Compliance:
IAM Roles
IAM Policies
IAM Groups
IAM Users
1 – Configuring Credentials
Komiser needs your AWS credentials to authenticate with AWS services. The CLI supports multiple methods of supporting these credentials. By default the CLI will source credentials automatically from its default credential chain. The common items in the credentials chain are the following:
Environment Credentials
AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY
AWS_DEFAULT_REGION
Shared Credentials file (~/.aws/credentials)
EC2 Instance Role Credentials
To get started, create a new IAM user, and assign to it this following IAM policy:
Note: The Komiser CLI is updated frequently with support for new AWS services. To see if you have the latest version, see the project Github repository.
After you install the Komiser CLI, you may need to add the path to the executable file to your PATH variable.
Few days ago, Google has announced the beta release of Flutter at Mobile World Congress 2018. A mobile UI framework to build native apps for both iOS and Android. It uses Dart to write application. The code is compiled using the standard Android and iOS toolchains for the specifc mobile platform, hence, better performance and startup times.
Excellent editor integretation: Android Studio & Visual Studio Code.
Single codebase for iOS and Android, full native performance (does not use JavaScript as a bridge or WebViews) .
React Native competitor.
Dart feels more Java, easy for Java developers to jump on it.
It use Widgets, so for people coming from web developement background everything should seem very familiar.
It might end the Google vs Oracle Java wars.
So it was a great opportunity to get my hands dirty and create a Flutter application based on Serverless Golang API I built in my previous post “Serverless Golang API with AWS Lambda”
The Flutter application will call API Gateway which will invoke a Lambda Function that will use TMDB API to get a list of movies airing this week in theatres in real-time. The application will consume the JSON response and display results in a ListView.
Let’s initialize our _movies variable with a list of movies by invoking API Gateway, we will iterate through the JSON response, and add the movies using the _addMovie function:
Now we just need to display movies in a scrolling ListView. Flutter comes with a suit of powerful basic widgets. In the code below I used the Text, Row, Image widgets. In addition to Padding & Align components to display properly a Movie item: