AWS Elastic Beanstalk is one of the most used PaaS today, it allows you to deploy your application without provisioning the underlying infrastructure while maintaining the high availability of your application. However, it’s painful to use due to the lack of documentation and real-world scenarios. In this post, I will walk you through how to use Elastic Beanstalk to deploy Docker containers from scratch. Followed by how to automate your deployment process with a Continuous Integration pipeline. At the end of this post, you should be familiar with advanced topics like debugging and monitoring of your applications in EB.
1 – Environment Setup
To get started, create a new Application using the following AWS CLI command:
Next, we will create a Dockerfile to build the Docker image. Go is a compiled language, therefore we can use the Docker multi-stage feature to build a lightweight Docker image:
1 2 3 4 5 6 7 8 9 10 11 12 13
FROM golang:1.10 as builder WORKDIR /go/src/github.com/mlabouardy/docker-eb-ci-mon COPY main.go . RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
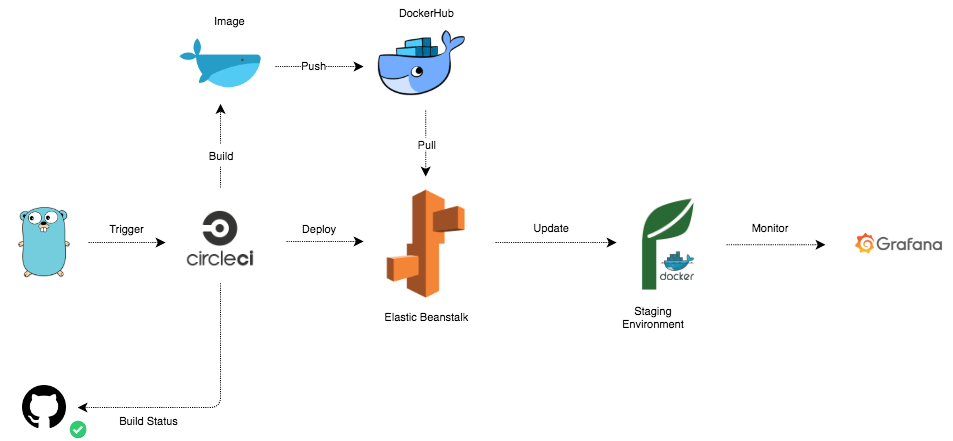
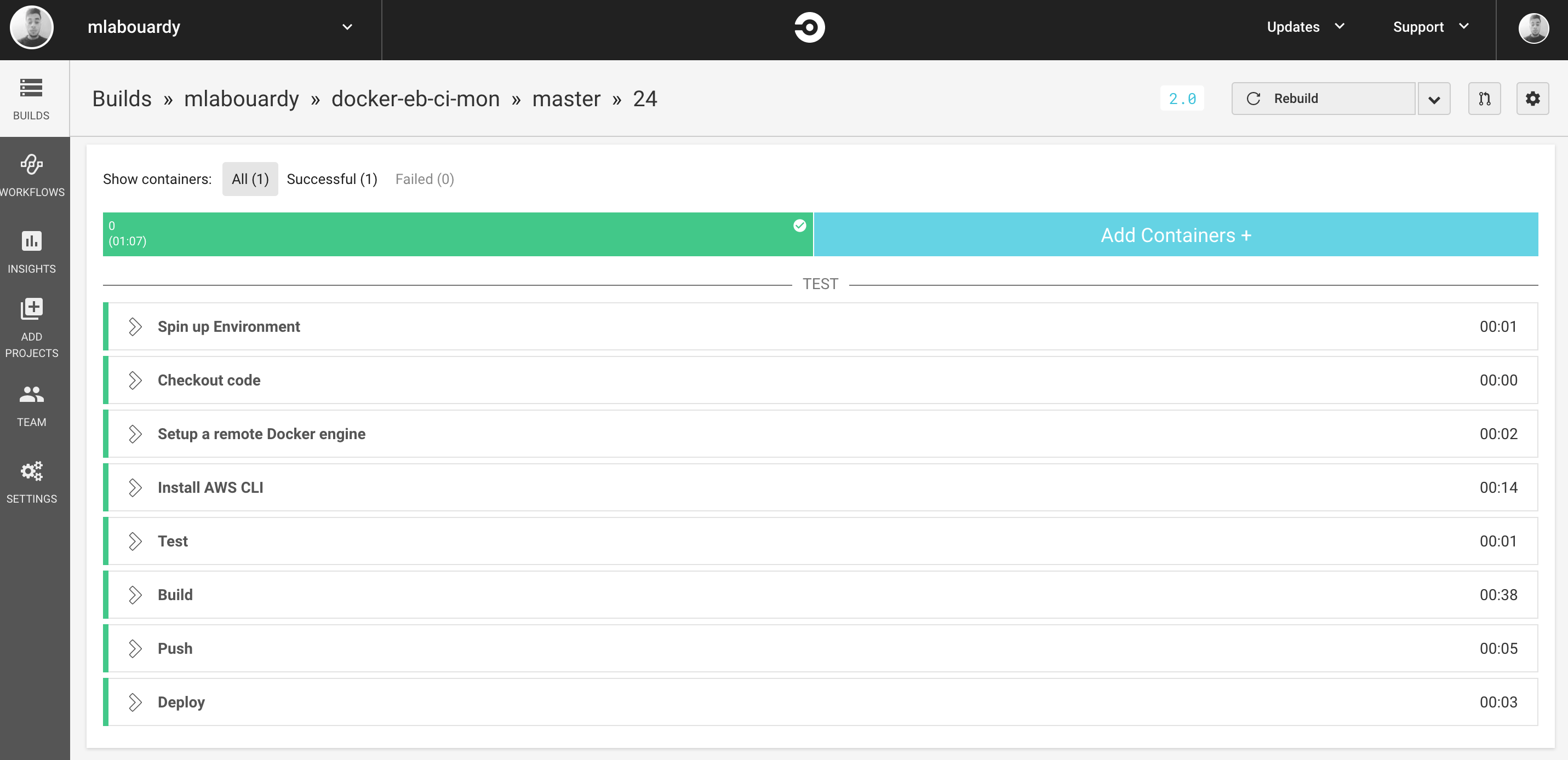
The pipeline will firstly prepare the environment, installing the AWS CLI. Then run unit tests. Next, a Docker image will be built, then pushed to DockerHub. Last step is creating a new application bundle and deploying the bundle to Elastic Beanstalk.
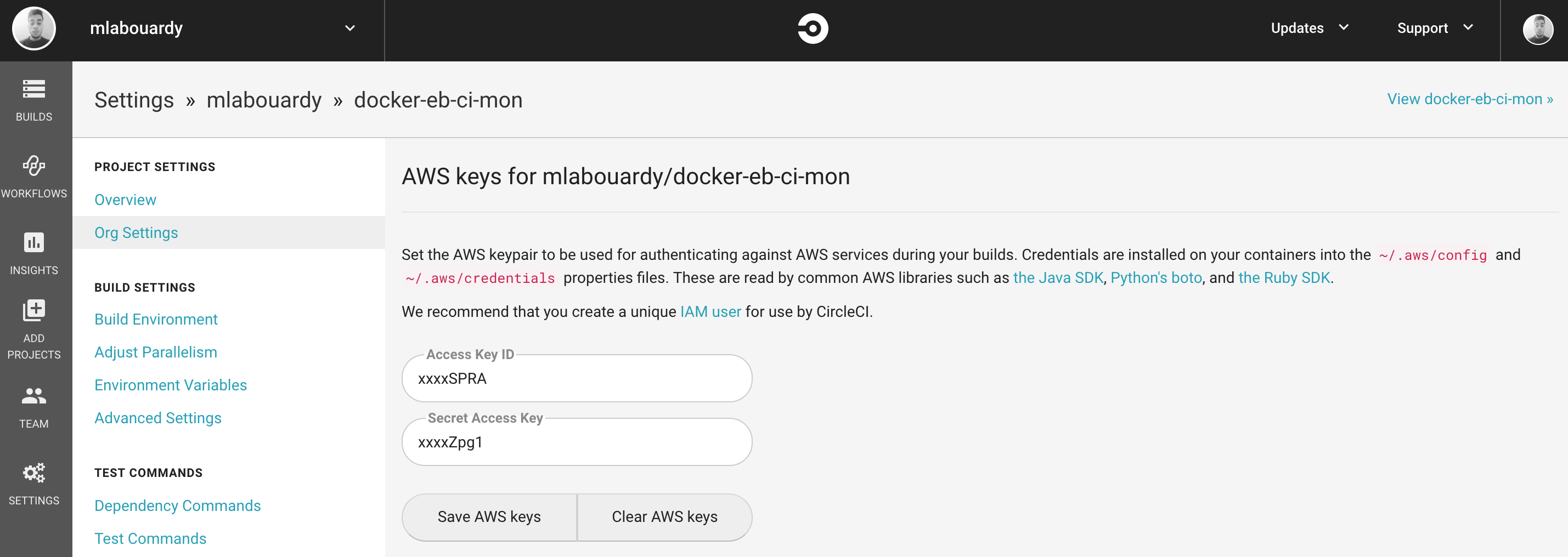
In order to grant Circle CI permissions to call AWS operations, we need to create a new IAM user with following IAM policy:
Generate AWS access & secret keys. Then, head back to Circle CI and click on the project settings and paste the credentials :
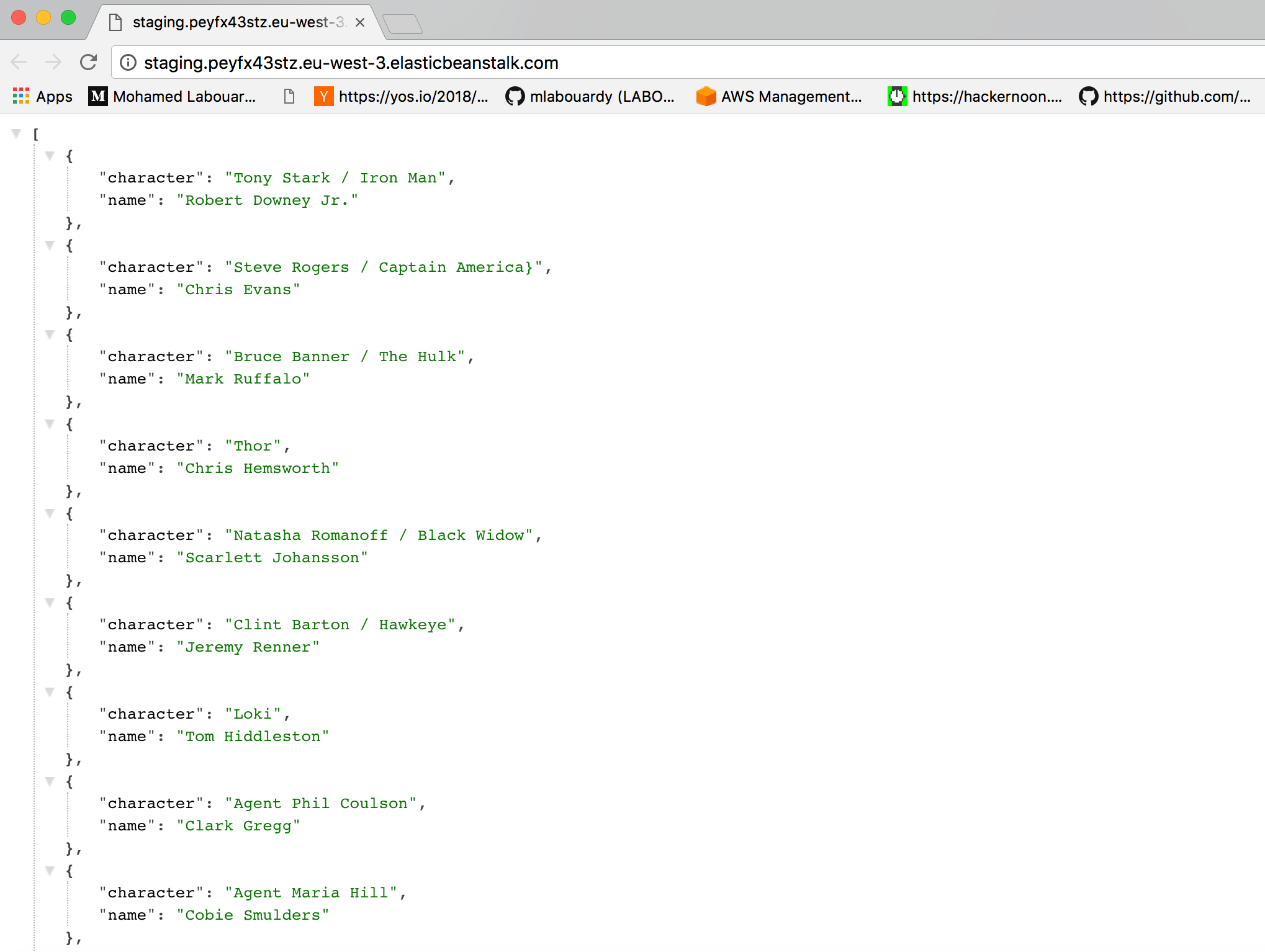
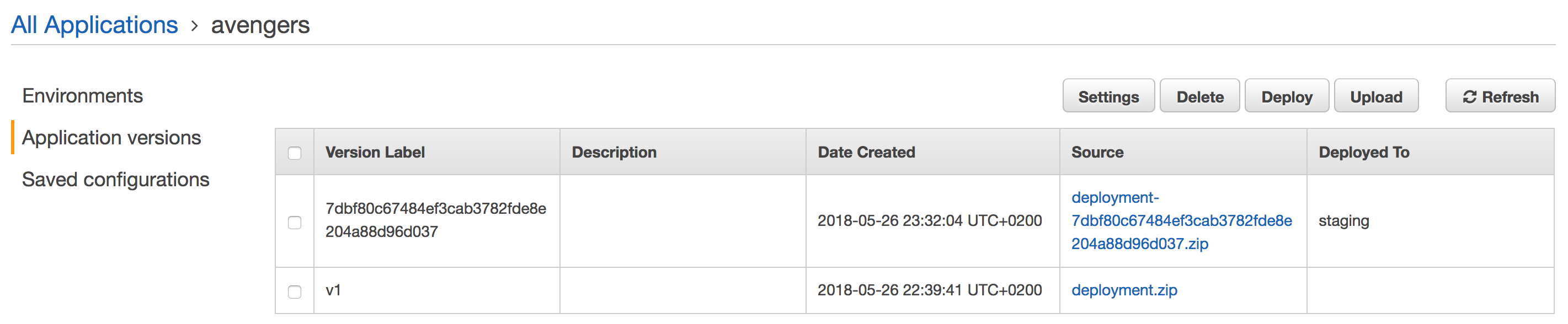
Now, everytime you push a change to your code repository, a build will be triggered:
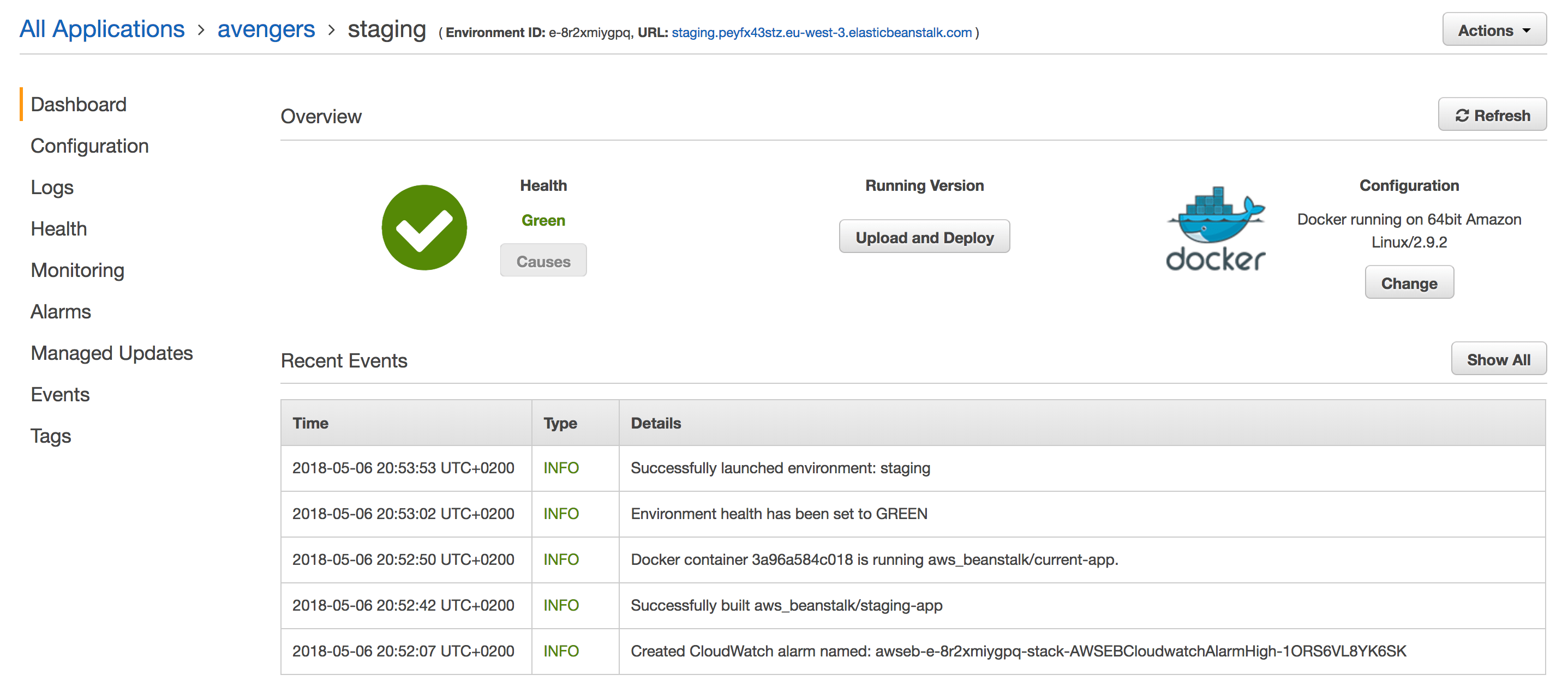
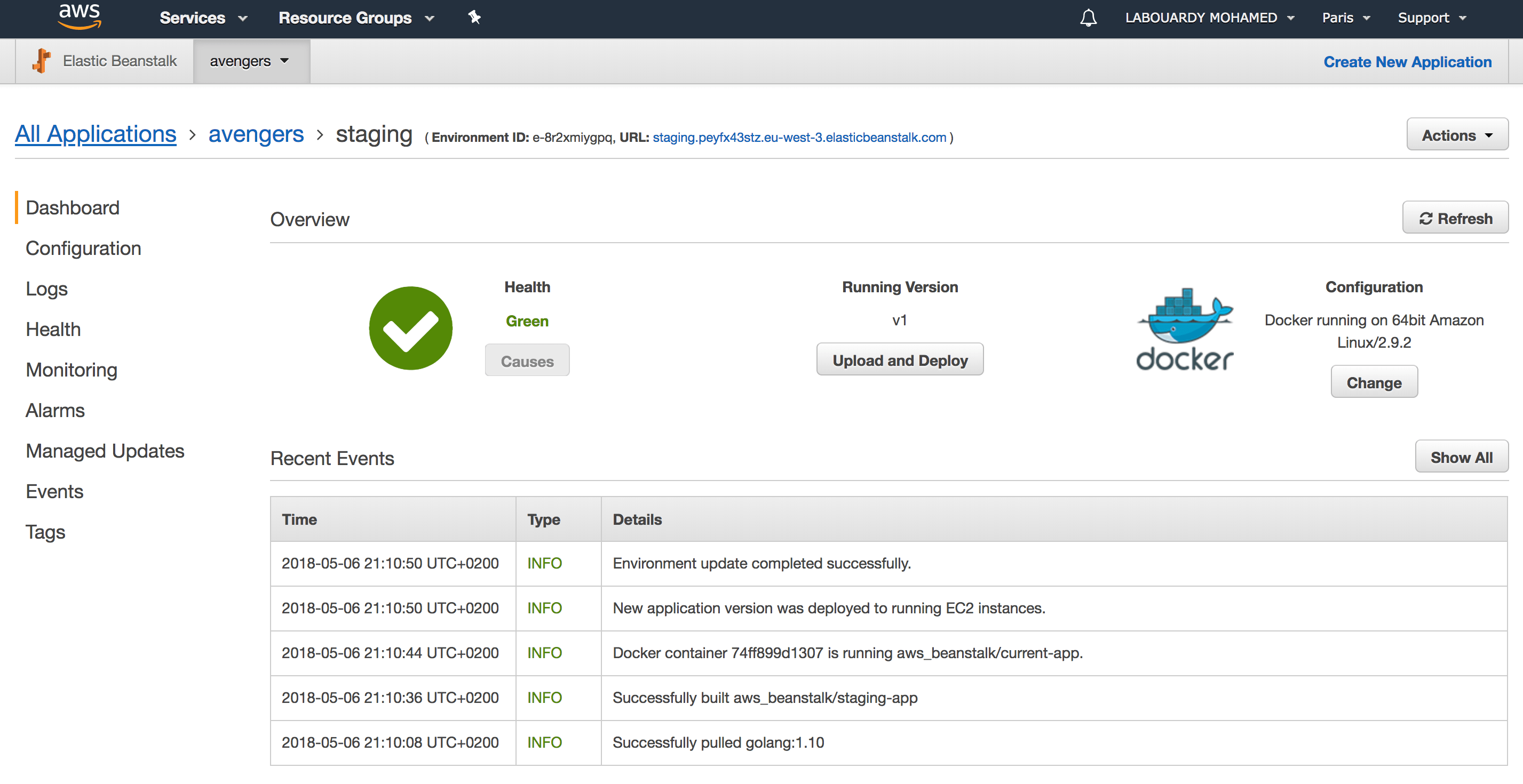
And a new version will be deployed automatically to Elastic Beanstalk:
3 – Monitoring
Monitoring your applications is mandatory. Unfortunately, CloudWatch doesn’t expose useful metrics like Memory usage of your applications in Elastic Beanstalk. Hence, in this part, we will solve this issue by creating our custom metrics.
I will install a data collector agent on the instance. The agent will collect metrics and push them to a time-series database.
To install the agent, we will use .ebextensions folder, on which we will create 3 configuration files:
01-install-telegraf.config: install Telegraf on the instance
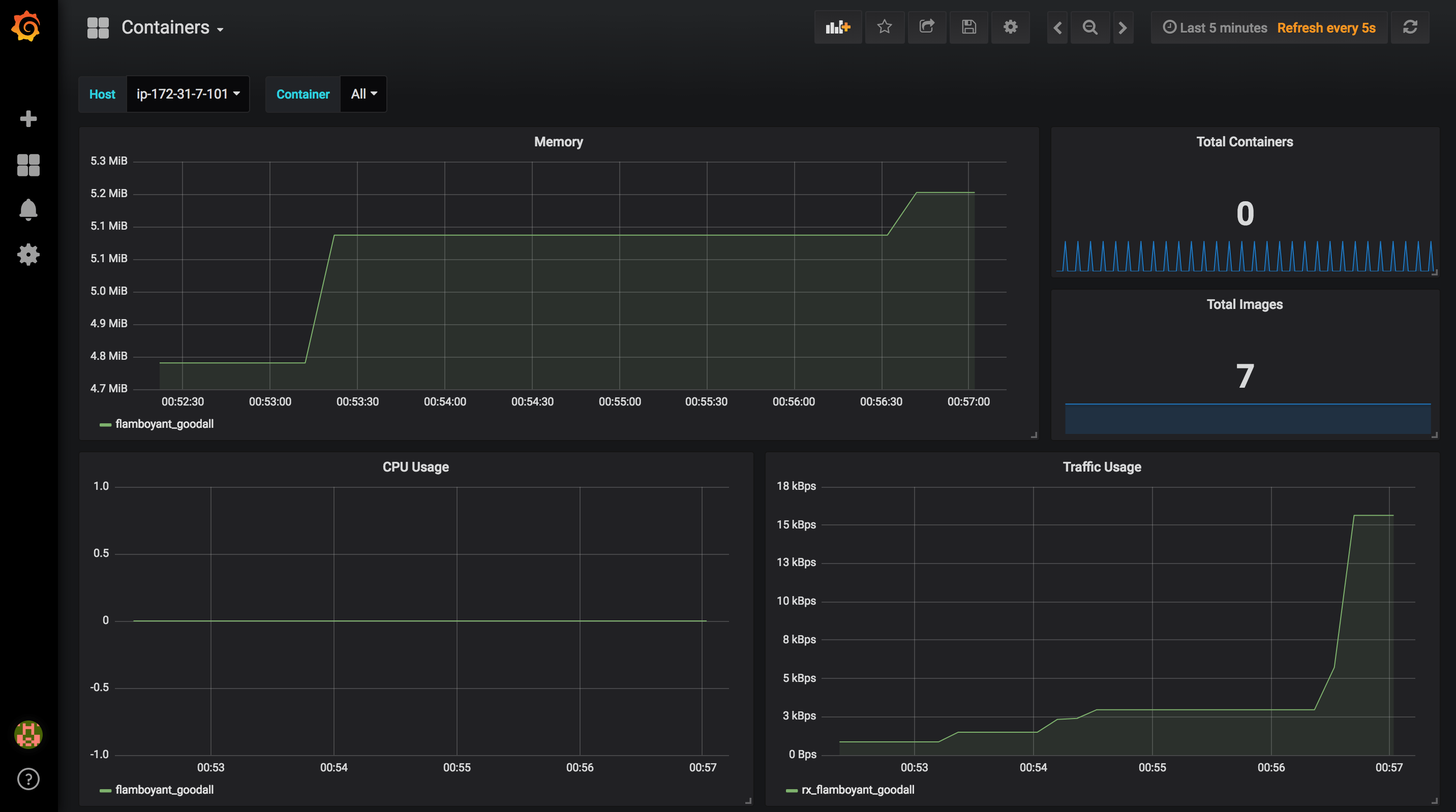
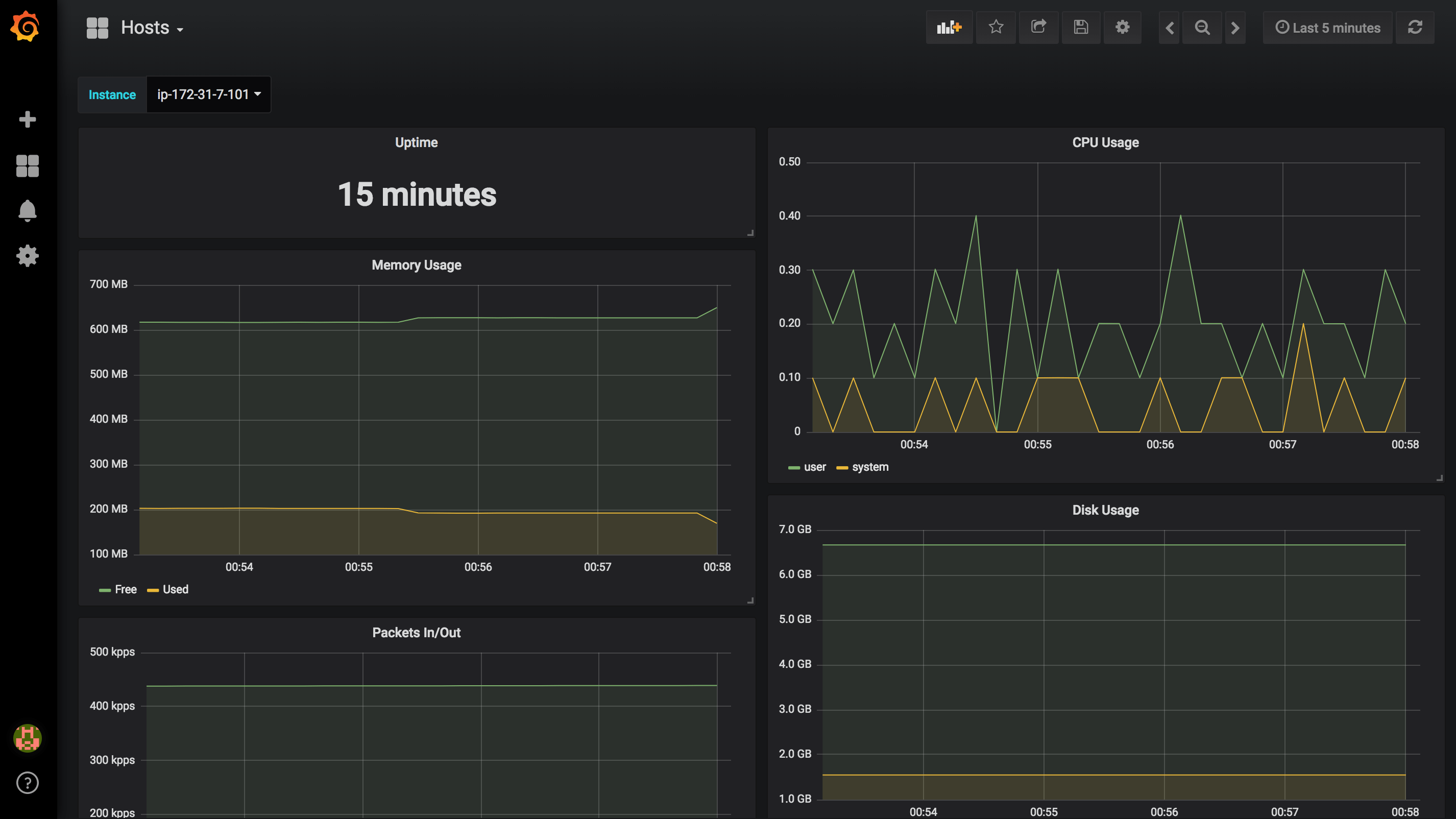
Once the application version is deployed to Elastic Beanstalk, metrics will be pushed to your timeseries database. In this example, I used InfluxDB as data storage and I created some dynamic Dashboards in Grafana to visualize metrics in real-time:
Containers:
Hosts:
Note: for in-depth explaination on how to configure Telegraf, InfluxDB & Grafana read my previous article.
Full code can be found on my GitHub. Make sure to drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy