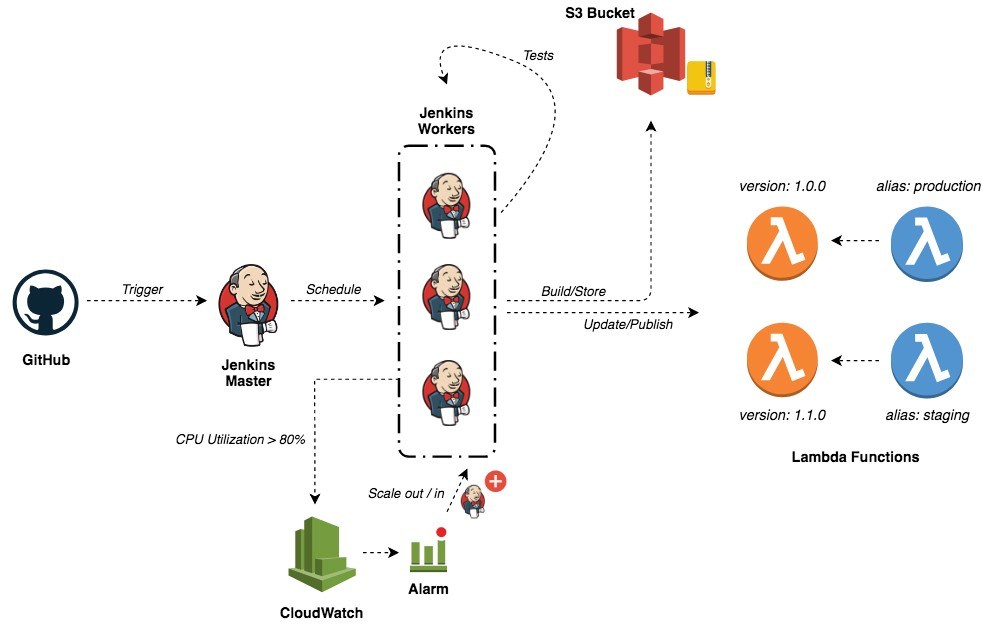
The following post will walk you through how to build a CI/CD pipeline to automate the deployment process of your Serverless applications and how to use features like code promotion, rollbacks, versions, aliases and blue/green deployment. At the end of this post, you will be able to build a pipeline similar to the following figure:
For the sake of simplicity, I wrote a simple Go based Lambda function that calculates the Fibonacci number:
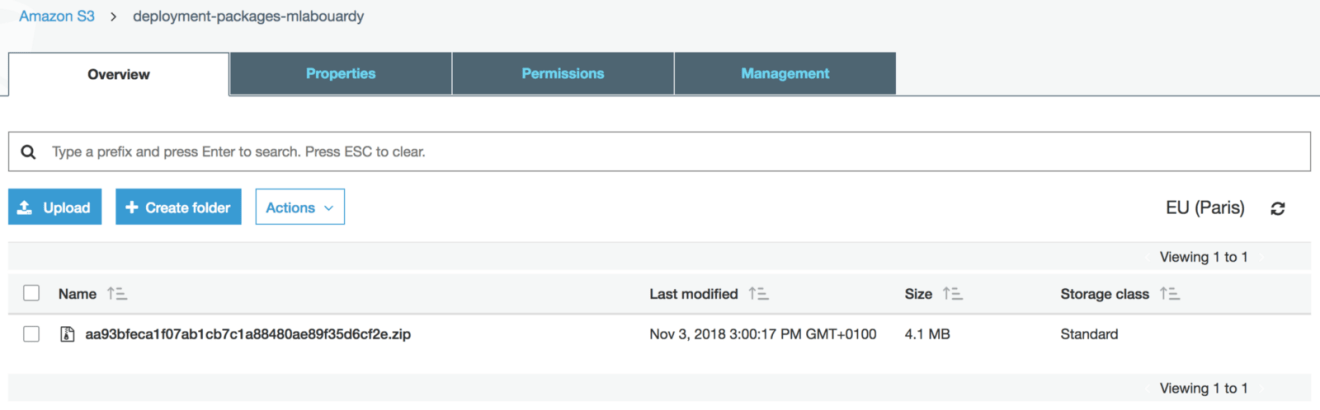
To create the function in AWS Lambda and all the necessary AWS services, I used Terraform. An S3 bucket is needed to store all the deployment packages generated through the development lifecycle of the Lambda function:
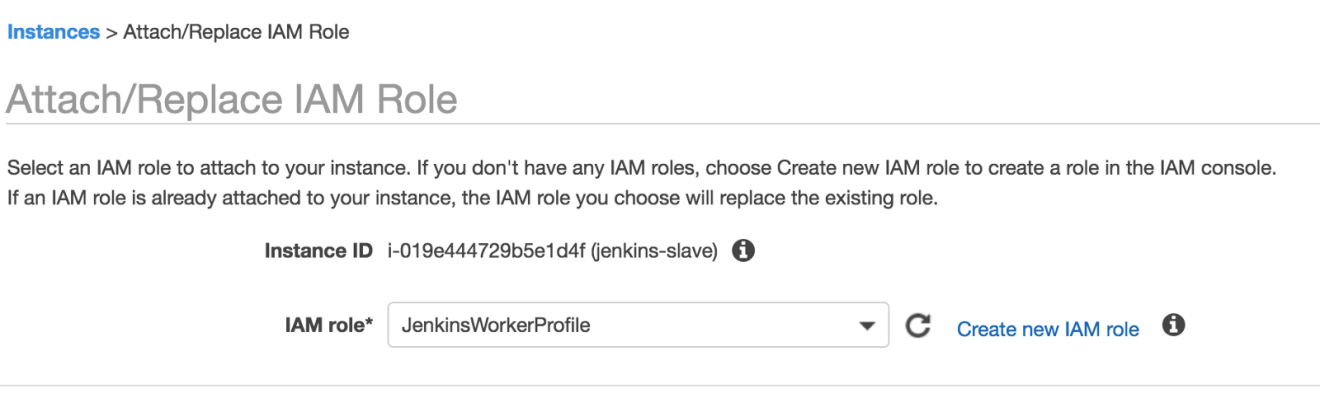
The build server needs to interact with S3 bucket and Lambda functions. Therefore, an IAM instance role must be created with S3 and Lambda permissions:
Next, build the deployment package with the following commands:
1 2 3 4
# Build linux binary GOOS=linux go build -o main main.go # Create a zip file zip deployment.zip main
Then, issue the terraform apply command to create the resources:
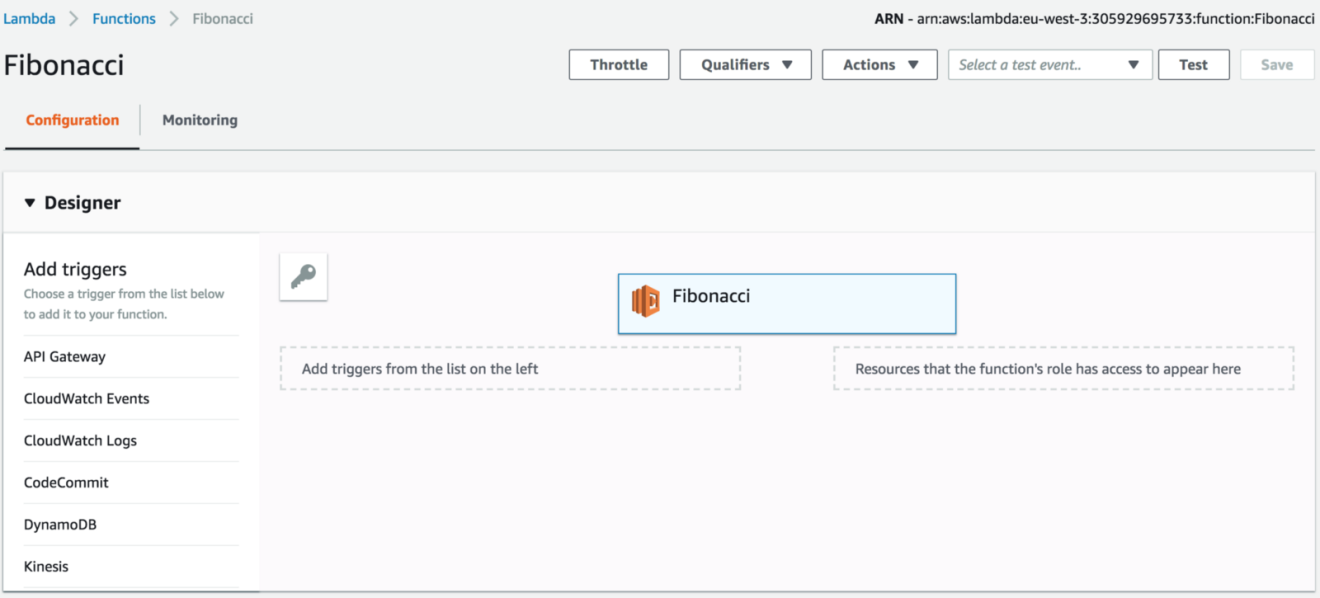
Sign in to AWS Management Console and navigate to Lambda Console, a new function called “Fibonacci” should be created:
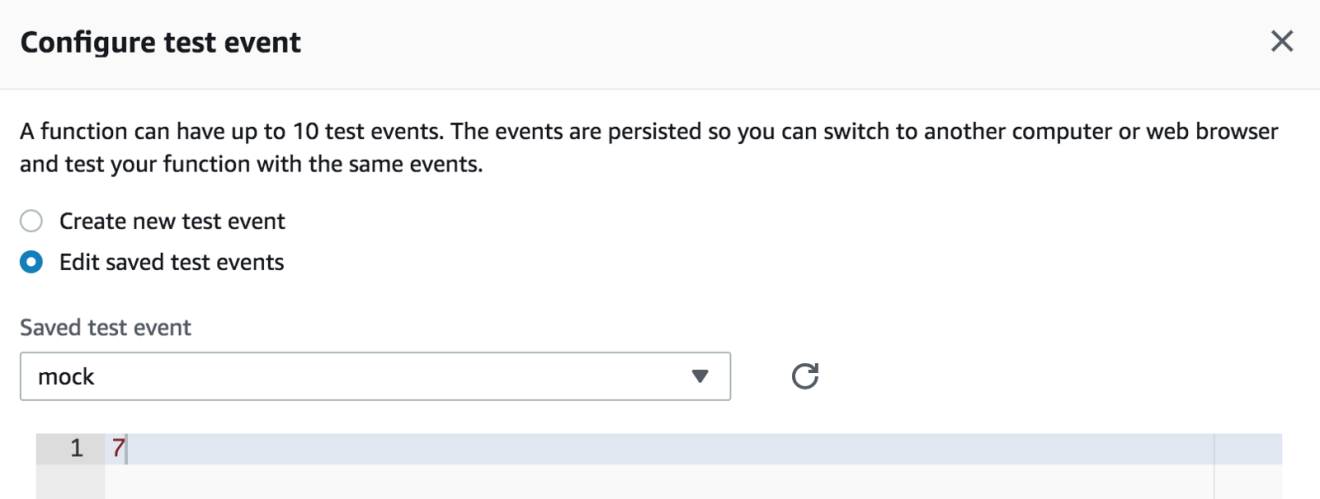
You can test it out, by mocking the input from the “Select a test event” dropdown list:
If you click on “Test” button the Fibonacci number of 7 will be returned:
So far our function is working as expected. However, how can we ensure each changes to our codebase doesn’t break things ? That’s where CI/CD comes into play, the idea is making all code changes and features go through a complex pipeline before integrating them to the master branch and deploying it to production.
You need a Jenkins cluster with at least a single worker (with Go preinstalled), you can follow my previous post for a step by step guide on how to build a Jenkins cluster on AWS from scratch.
Prior to the build, the IAM instance role (created with Terraform) with the write access to S3 and the update operations to Lambda must be configured on the Jenkins workers:
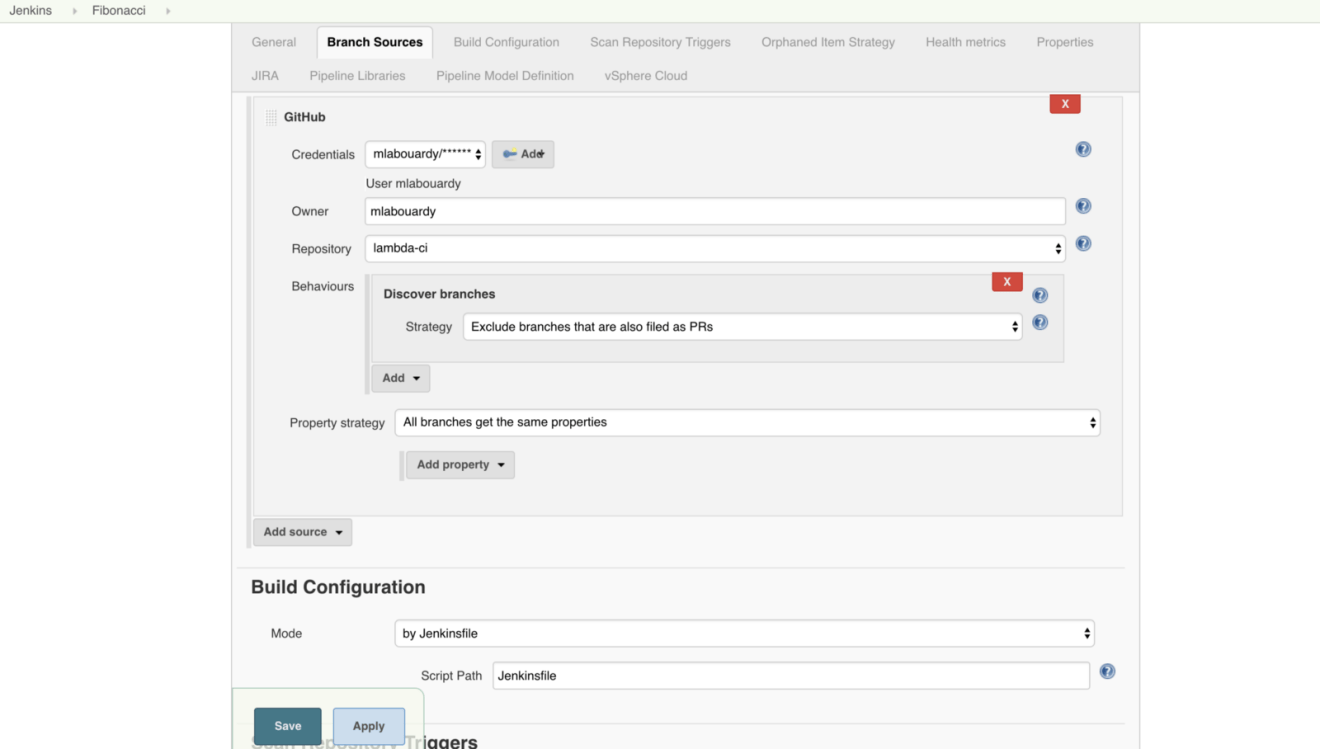
Jump back to Jenkins Dashboard and create new multi-branch project and configure the GitHub repository where the code source is versioned as follows:
Create a new file called Jenkinsfile, it defines a set of steps that will be executed on Jenkins (This definition file must be committed to the Lambda function’s code repository):
Test: check whether our code is well formatted and follows Go best practices and run unit tests.
Build: build a binary and create the deployment package.
Push: store the deployment package (.zip file) to an S3 bucket.
Deploy: update the Lambda function’s code with the new artifact.
Note the usage of the git commit ID as a name for the deployment package to give a meaningful and significant name for each release and be able to roll back to a specific commit if things go wrong.
Once the project is saved, a new pipeline should be created as follows:
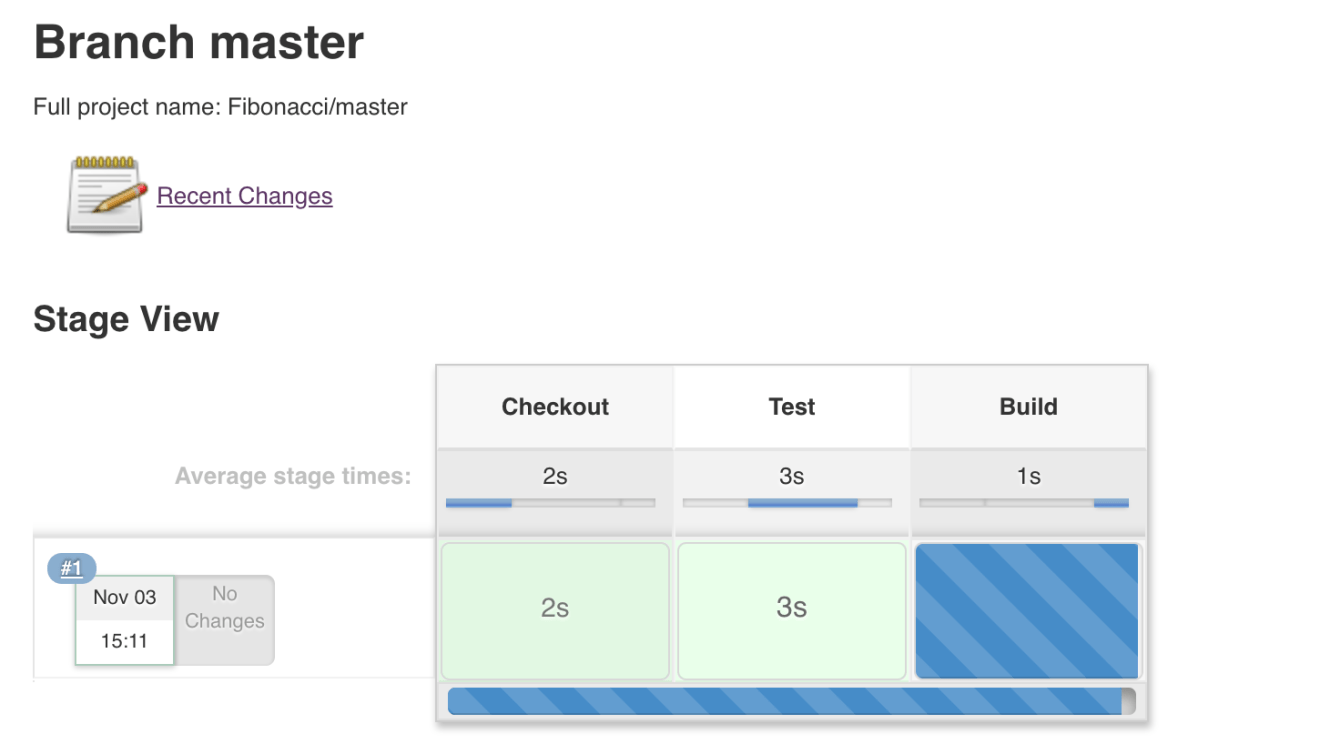
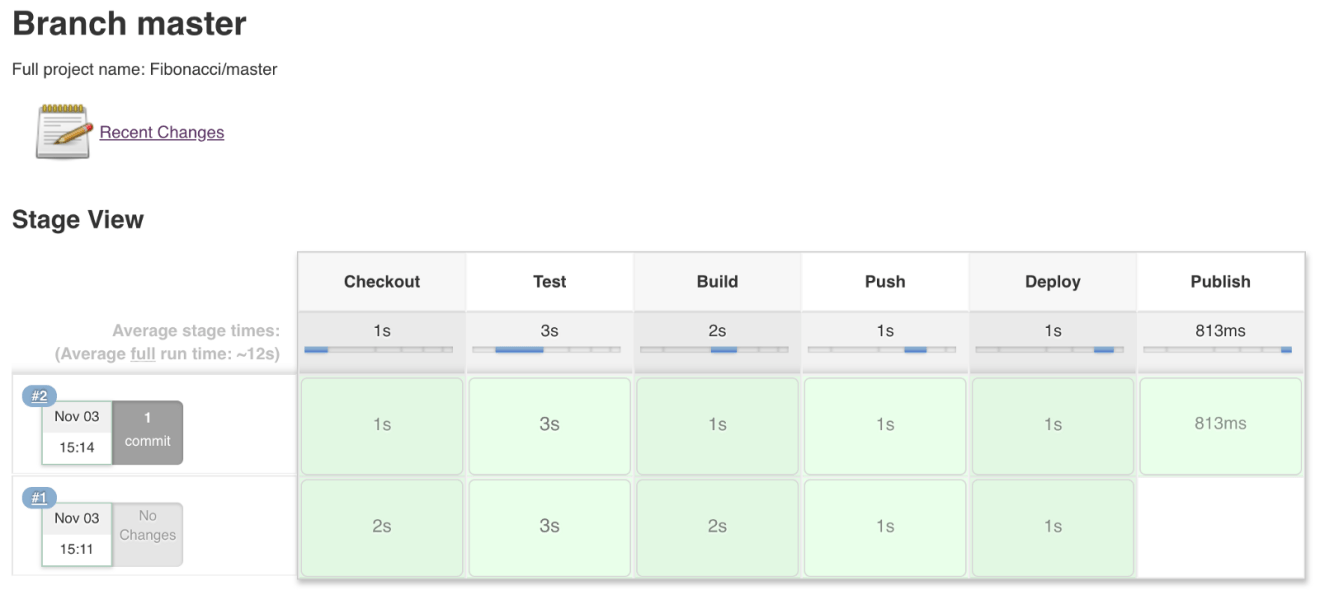
Once the pipeline is completed, all stages should be passed, as shown in the next screenshot:
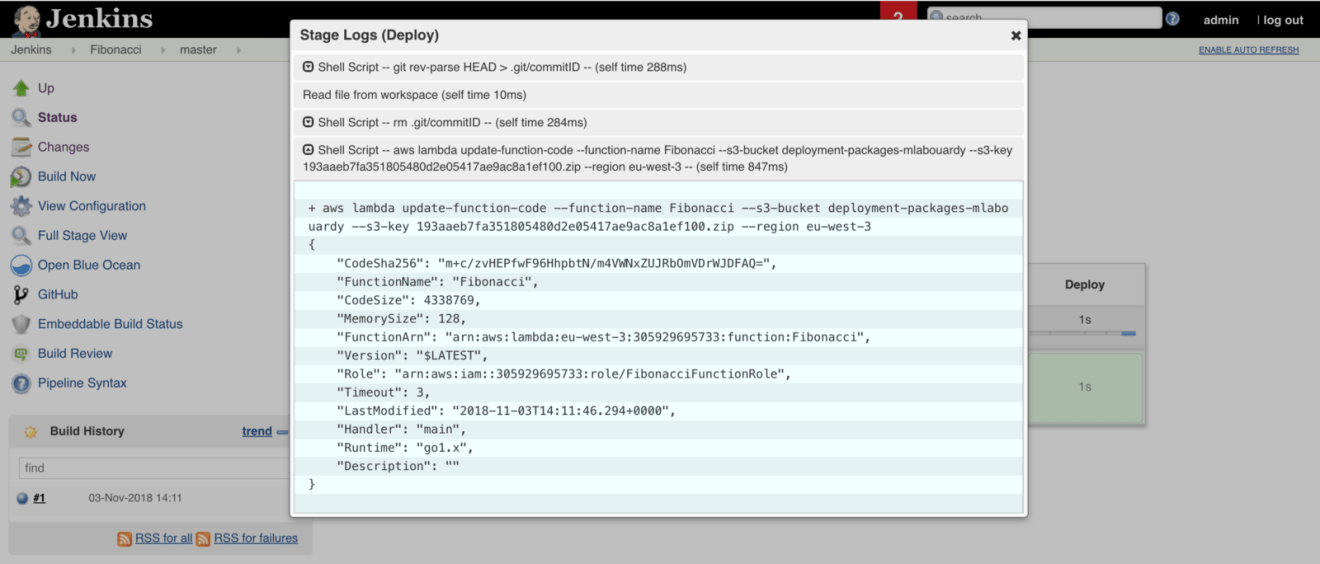
At the end, Jenkins will update the Lambda function’s code with the update-function-code command:
If you open the S3 Console, then click on the bucket used by the pipeline, a new deployment package should be stored with a key name identical to the commit ID:
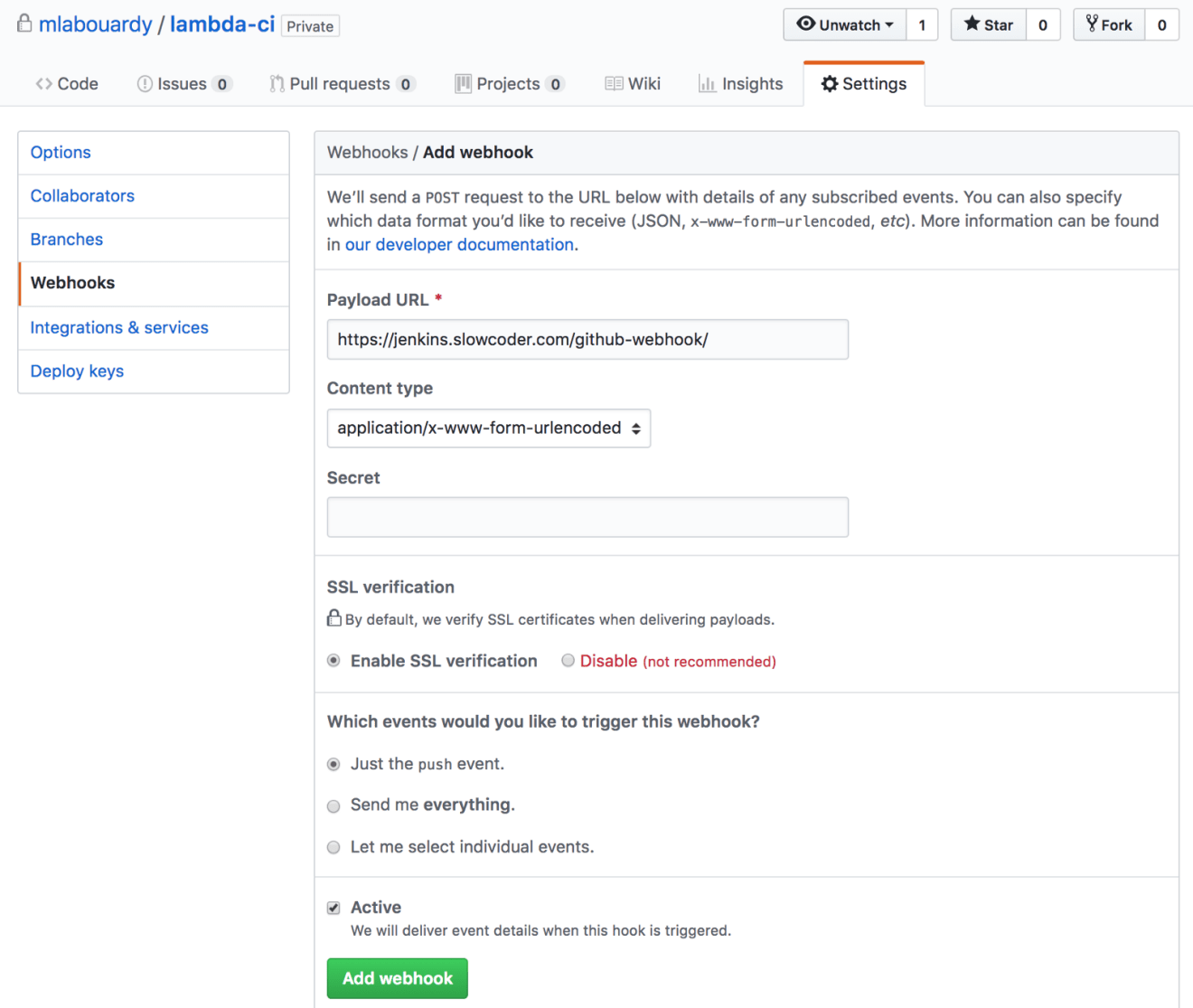
Finally, to make Jenkins trigger the build when you push to the code repository, click on “Settings” from your GitHub repository, then create a new webhook from “Webhooks”, and fill it in with a URL similar to the following:
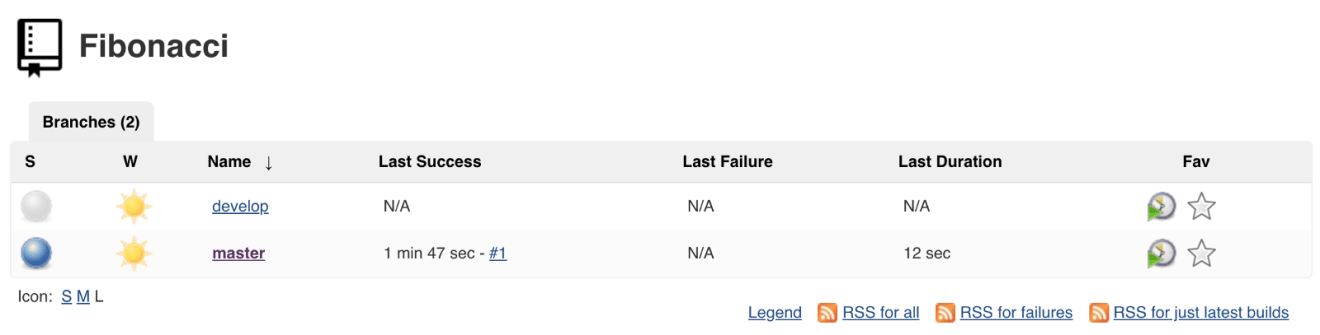
In case you’re using Git branching workflows (you should), Jenkins will discover automatically the new branches:
Hence, you must separate your deployment environments to test new changes without impacting your production. Therefore, having multiple versions of your Lambda functions makes sense.
Update the Jenkinsfile to add a new stage to publish a new Lambda function’s version, every-time you push (or merge) to the master branch:
if (env.BRANCH_NAME == 'master') { stage('Publish') { sh "aws lambda publish-version --function-name ${functionName} \ --region ${region}" } } }
def commitID() { sh 'git rev-parse HEAD > .git/commitID' def commitID = readFile('.git/commitID').trim() sh 'rm .git/commitID' commitID }
On the master branch, a new stage called “Published” will be added:
As a result, a new version will be published based on the master branch source code:
However, in agile based environment (Extreme programming). The development team needs to release iterative versions of the system often to help the customer to gain confidence in the progress of the project, receive feedback and detect bugs in earlier stage of development. As a result, small releases can be frequent:
AWS services using Lambda functions as downstream resources (API Gateway as an example) need to be updated every-time a new version is published -> operational overhead and downtime. USE aliases !!!
The alias is a pointer to a specific version, it allows you to promote a function from one environment to another (such as staging to production). Aliases are mutable, unlike versions, which are immutable.
That being said, create an alias for the production environment that points to the latest version published using the AWS command line:
def commitID() { sh 'git rev-parse HEAD > .git/commitID' def commitID = readFile('.git/commitID').trim() sh 'rm .git/commitID' commitID }
Like what you’re reading? Check out my book and learn how to build, secure, deploy and manage production-ready Serverless applications in Golang with AWS Lambda.
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.