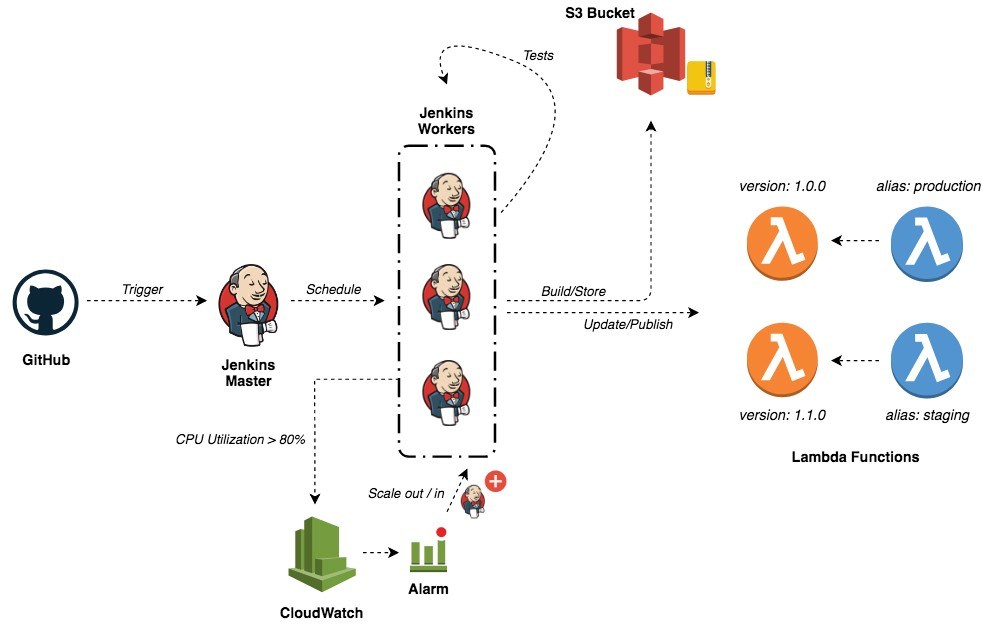
The following post will walk you through how to build a CI/CD pipeline to automate the deployment process of your Serverless applications and how to use features like code promotion, rollbacks, versions, aliases and blue/green deployment. At the end of this post, you will be able to build a pipeline similar to the following figure:
For the sake of simplicity, I wrote a simple Go based Lambda function that calculates the Fibonacci number:
To create the function in AWS Lambda and all the necessary AWS services, I used Terraform. An S3 bucket is needed to store all the deployment packages generated through the development lifecycle of the Lambda function:
The build server needs to interact with S3 bucket and Lambda functions. Therefore, an IAM instance role must be created with S3 and Lambda permissions:
Next, build the deployment package with the following commands:
1 2 3 4
# Build linux binary GOOS=linux go build -o main main.go # Create a zip file zip deployment.zip main
Then, issue the terraform apply command to create the resources:
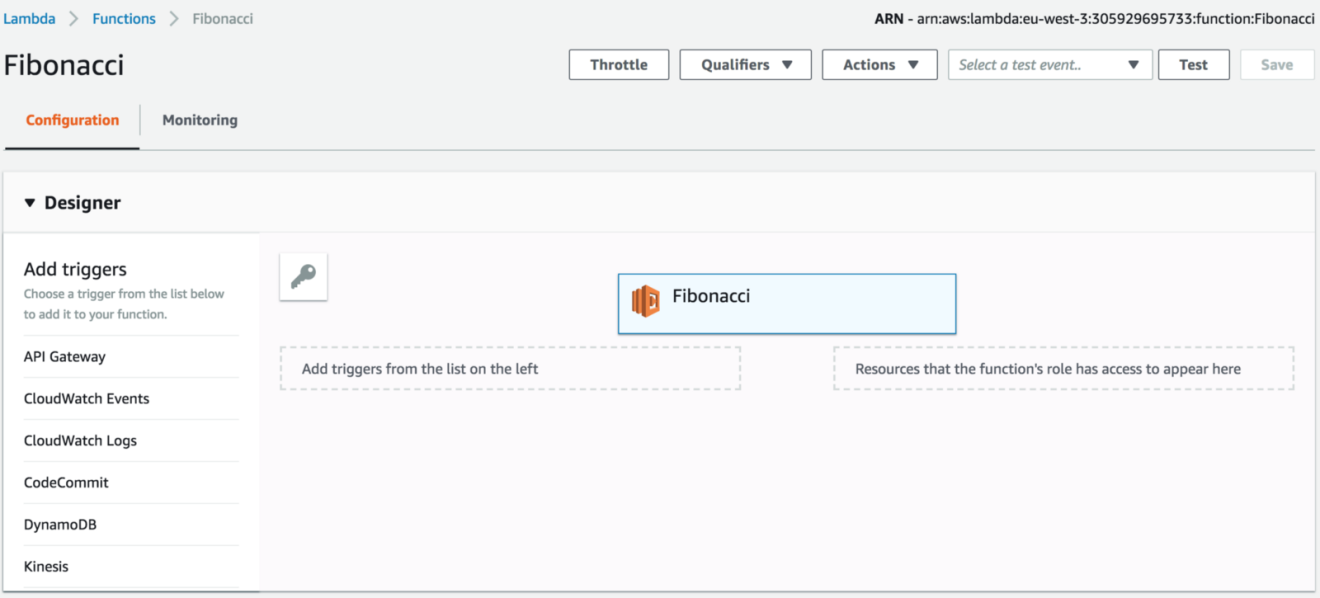
Sign in to AWS Management Console and navigate to Lambda Console, a new function called “Fibonacci” should be created:
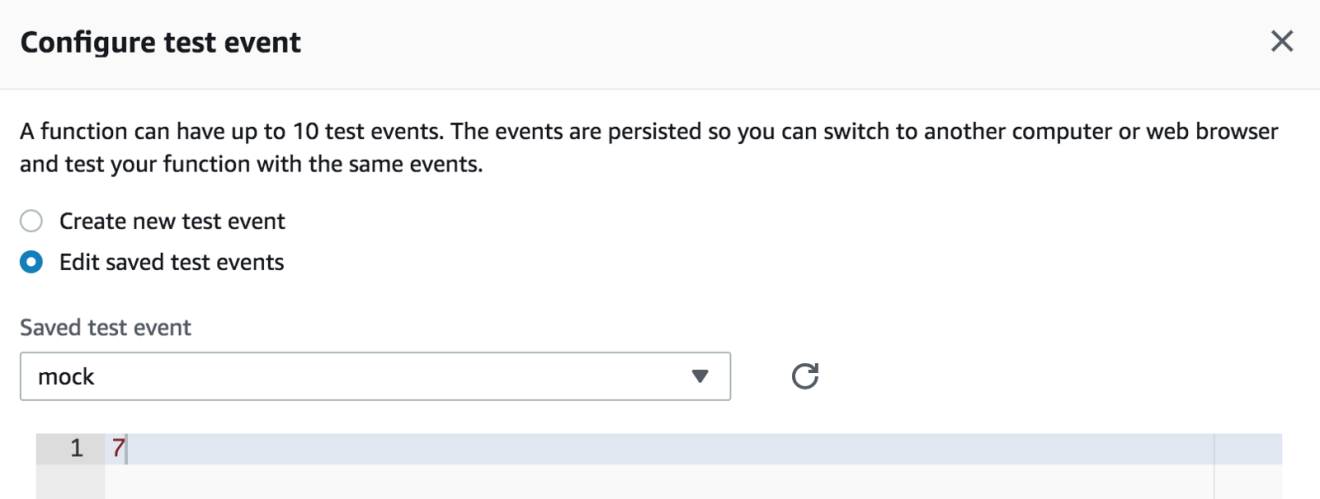
You can test it out, by mocking the input from the “Select a test event” dropdown list:
If you click on “Test” button the Fibonacci number of 7 will be returned:
So far our function is working as expected. However, how can we ensure each changes to our codebase doesn’t break things ? That’s where CI/CD comes into play, the idea is making all code changes and features go through a complex pipeline before integrating them to the master branch and deploying it to production.
You need a Jenkins cluster with at least a single worker (with Go preinstalled), you can follow my previous post for a step by step guide on how to build a Jenkins cluster on AWS from scratch.
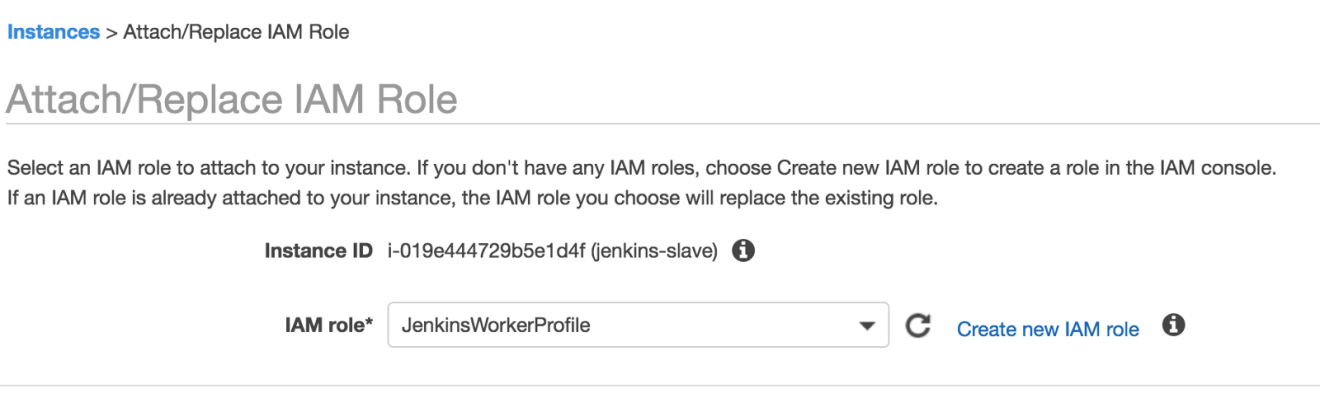
Prior to the build, the IAM instance role (created with Terraform) with the write access to S3 and the update operations to Lambda must be configured on the Jenkins workers:
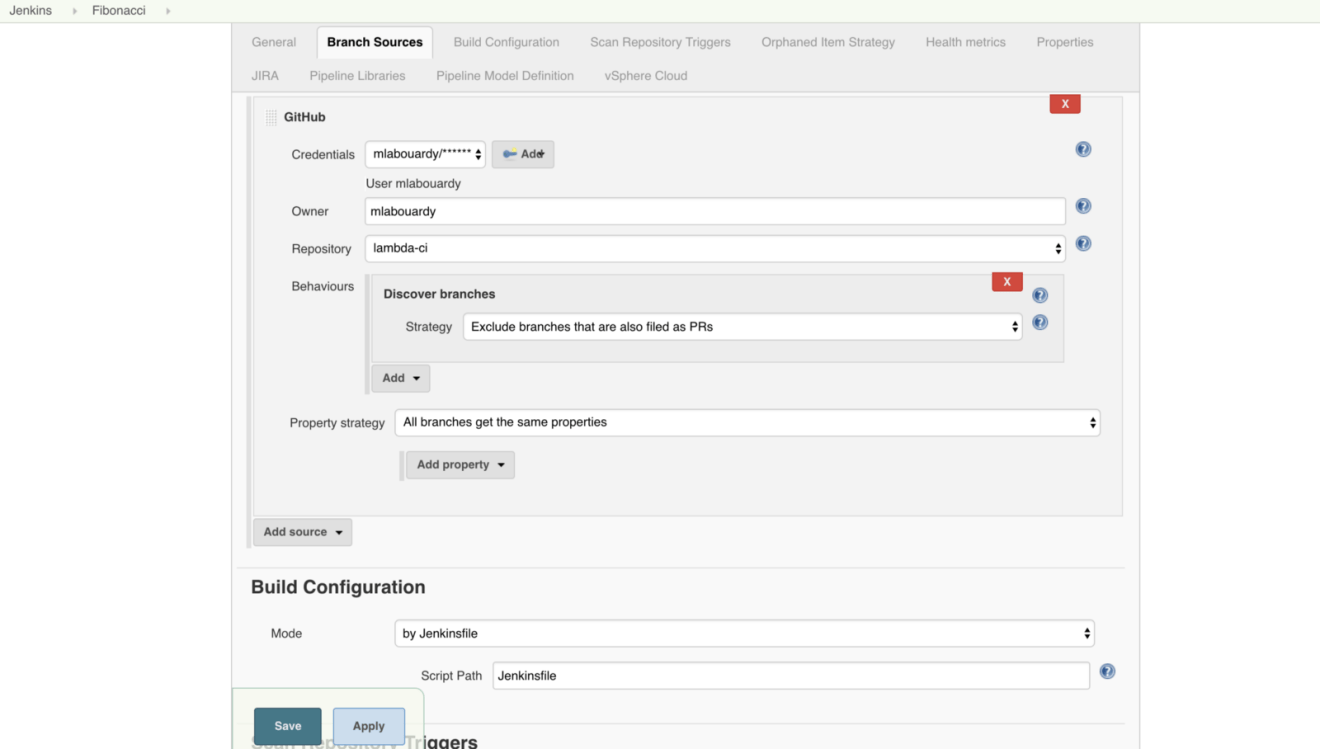
Jump back to Jenkins Dashboard and create new multi-branch project and configure the GitHub repository where the code source is versioned as follows:
Create a new file called Jenkinsfile, it defines a set of steps that will be executed on Jenkins (This definition file must be committed to the Lambda function’s code repository):
Test: check whether our code is well formatted and follows Go best practices and run unit tests.
Build: build a binary and create the deployment package.
Push: store the deployment package (.zip file) to an S3 bucket.
Deploy: update the Lambda function’s code with the new artifact.
Note the usage of the git commit ID as a name for the deployment package to give a meaningful and significant name for each release and be able to roll back to a specific commit if things go wrong.
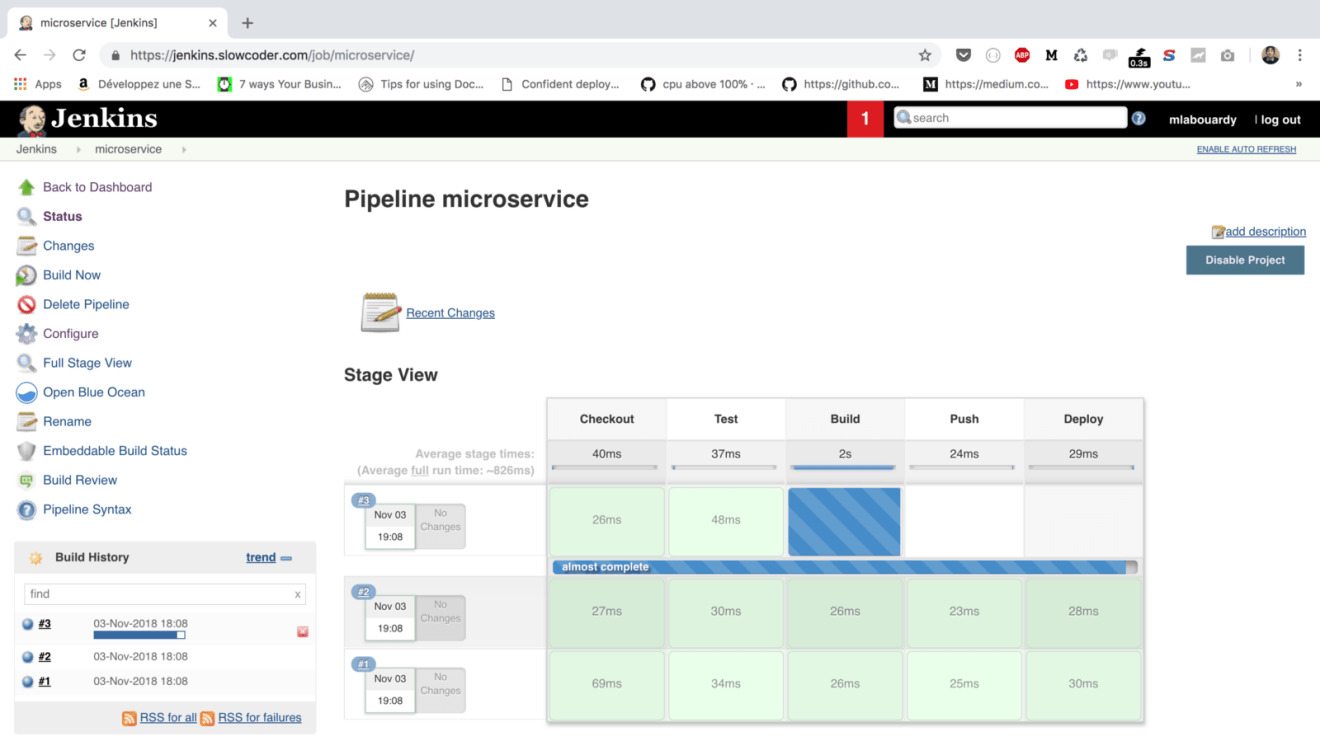
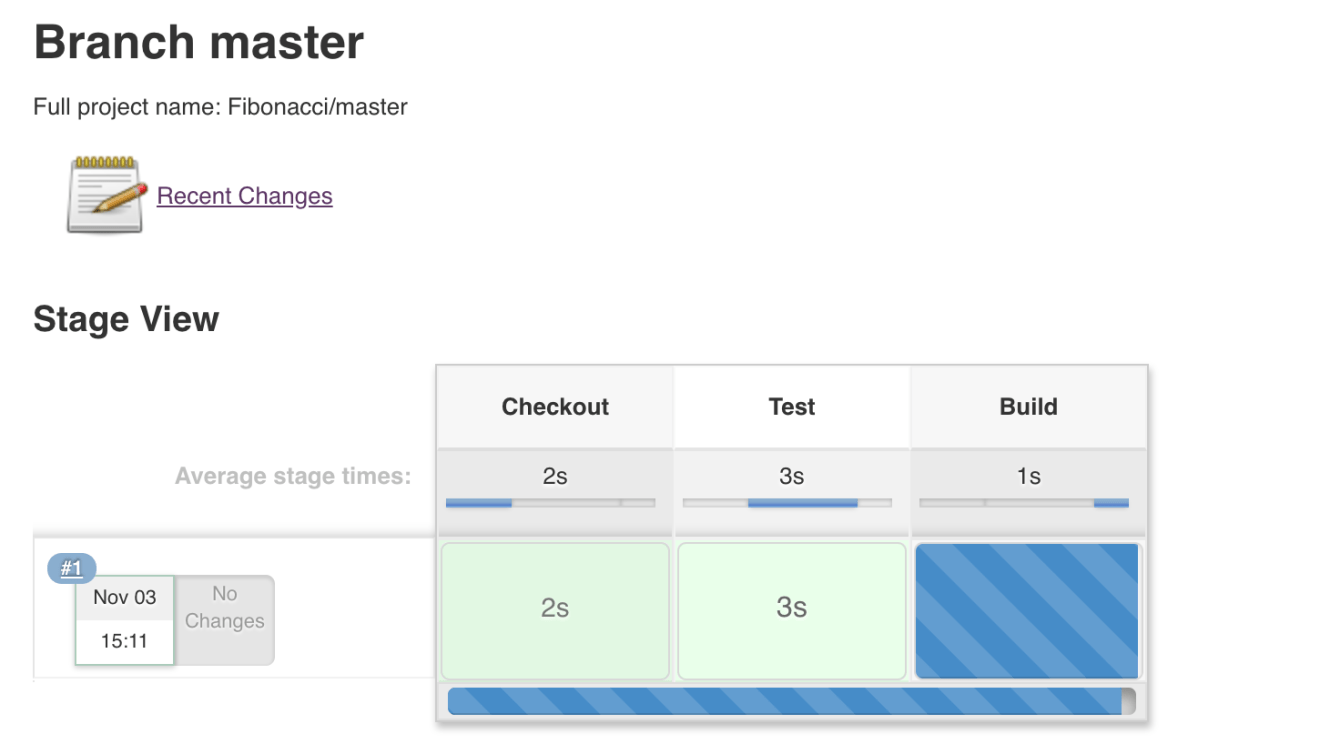
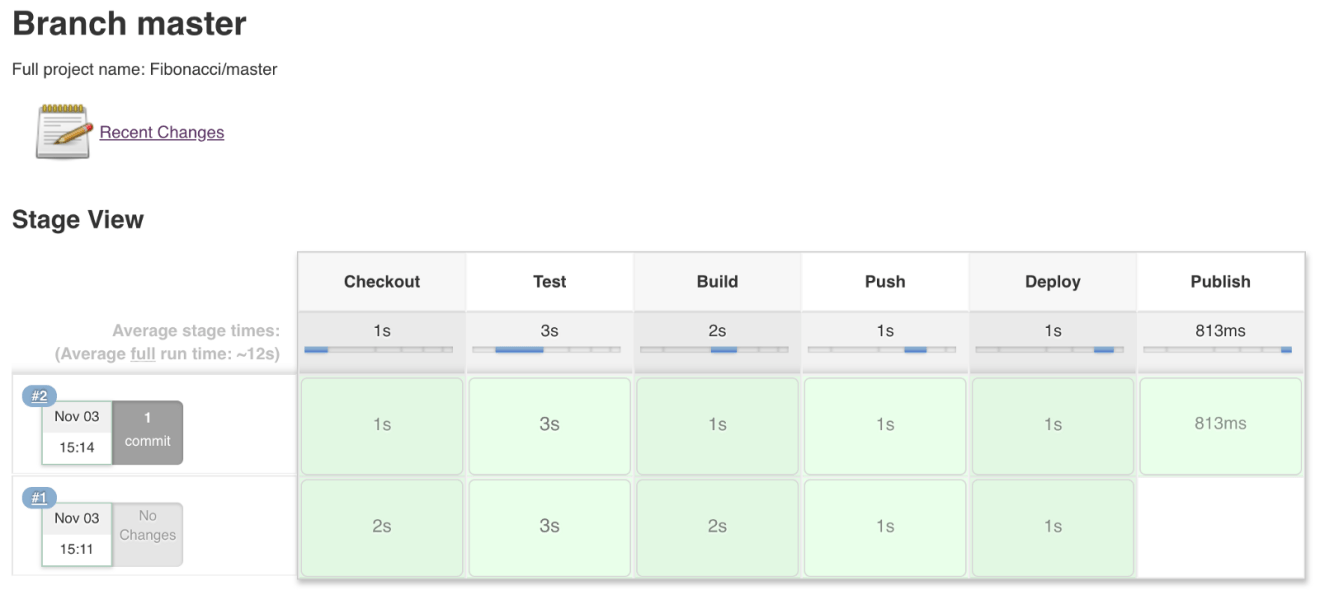
Once the project is saved, a new pipeline should be created as follows:
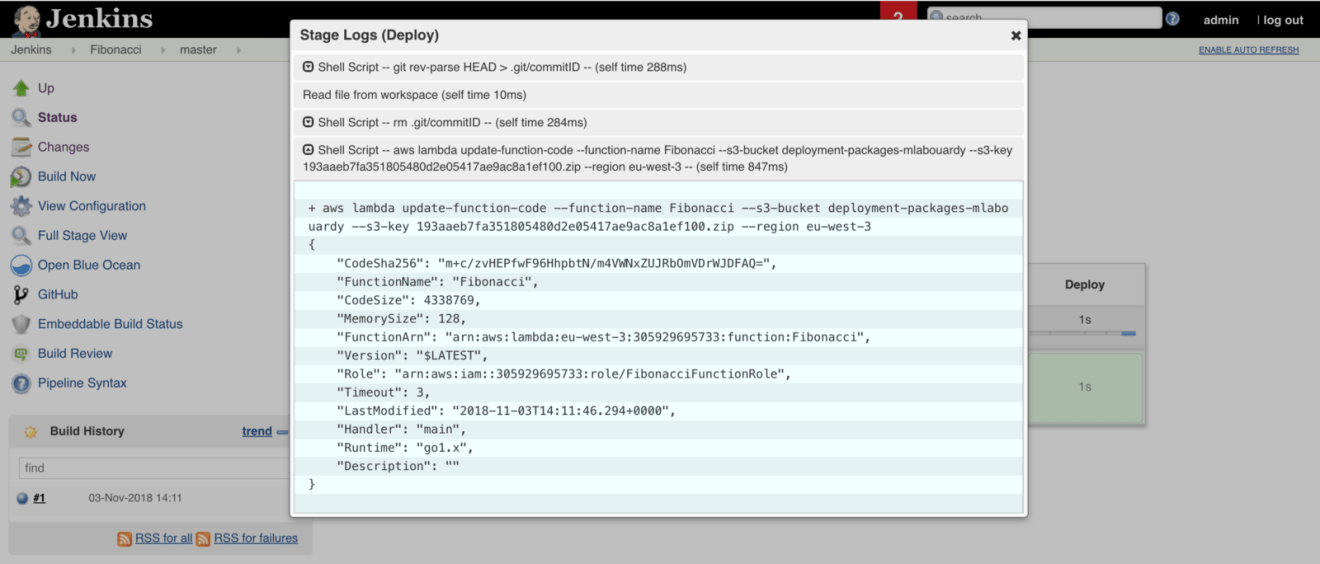
Once the pipeline is completed, all stages should be passed, as shown in the next screenshot:
At the end, Jenkins will update the Lambda function’s code with the update-function-code command:
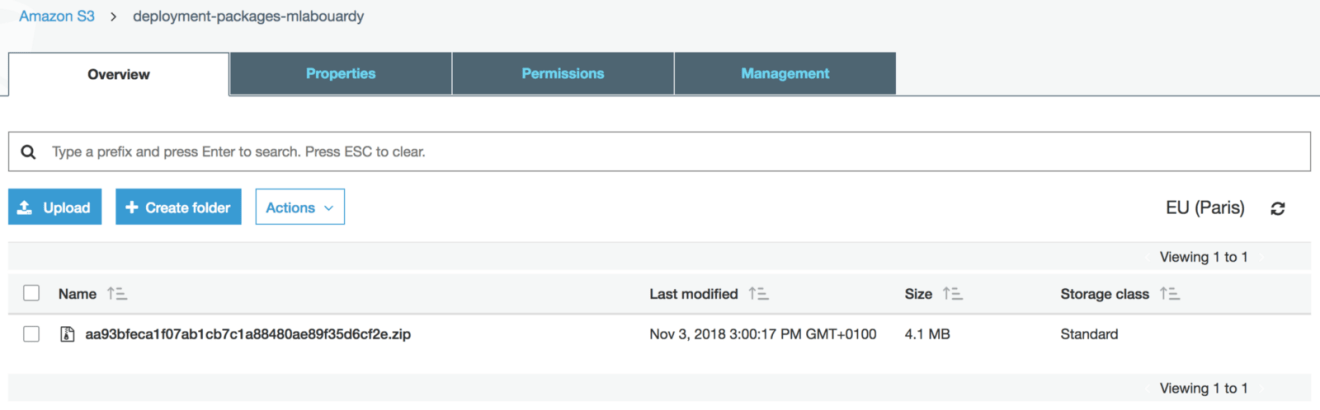
If you open the S3 Console, then click on the bucket used by the pipeline, a new deployment package should be stored with a key name identical to the commit ID:
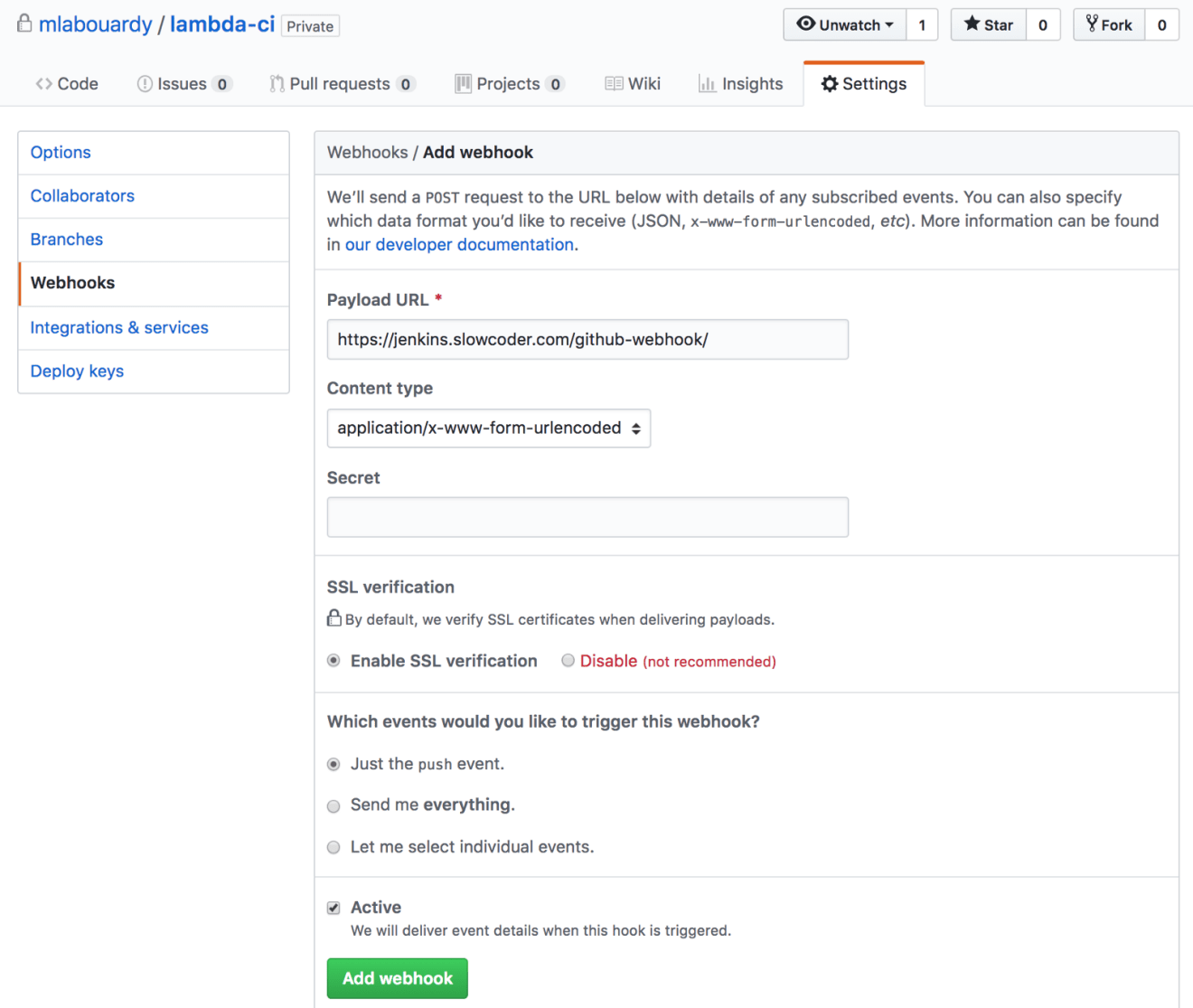
Finally, to make Jenkins trigger the build when you push to the code repository, click on “Settings” from your GitHub repository, then create a new webhook from “Webhooks”, and fill it in with a URL similar to the following:
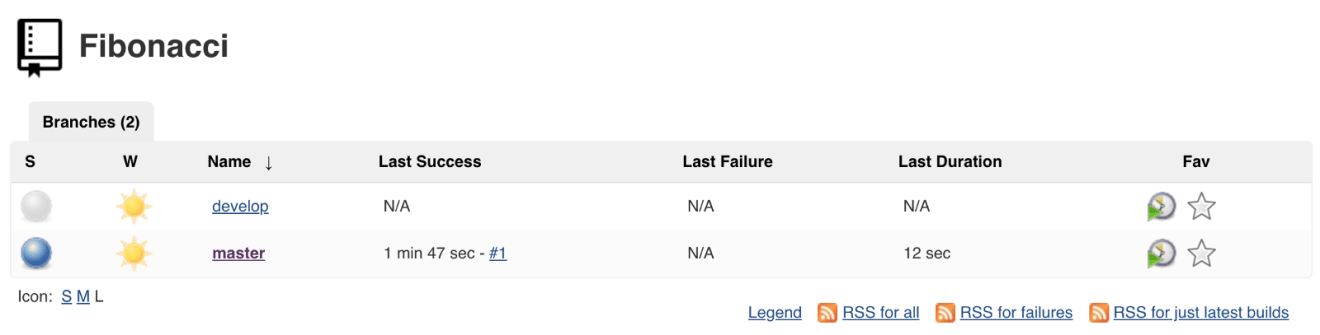
In case you’re using Git branching workflows (you should), Jenkins will discover automatically the new branches:
Hence, you must separate your deployment environments to test new changes without impacting your production. Therefore, having multiple versions of your Lambda functions makes sense.
Update the Jenkinsfile to add a new stage to publish a new Lambda function’s version, every-time you push (or merge) to the master branch:
if (env.BRANCH_NAME == 'master') { stage('Publish') { sh "aws lambda publish-version --function-name ${functionName} \ --region ${region}" } } }
def commitID() { sh 'git rev-parse HEAD > .git/commitID' def commitID = readFile('.git/commitID').trim() sh 'rm .git/commitID' commitID }
On the master branch, a new stage called “Published” will be added:
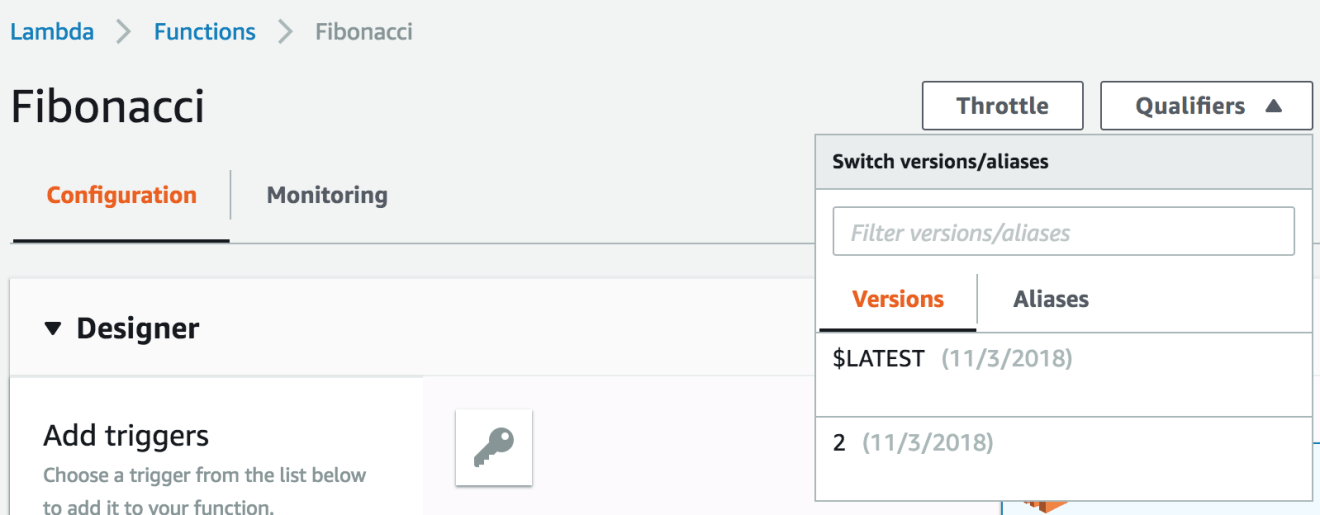
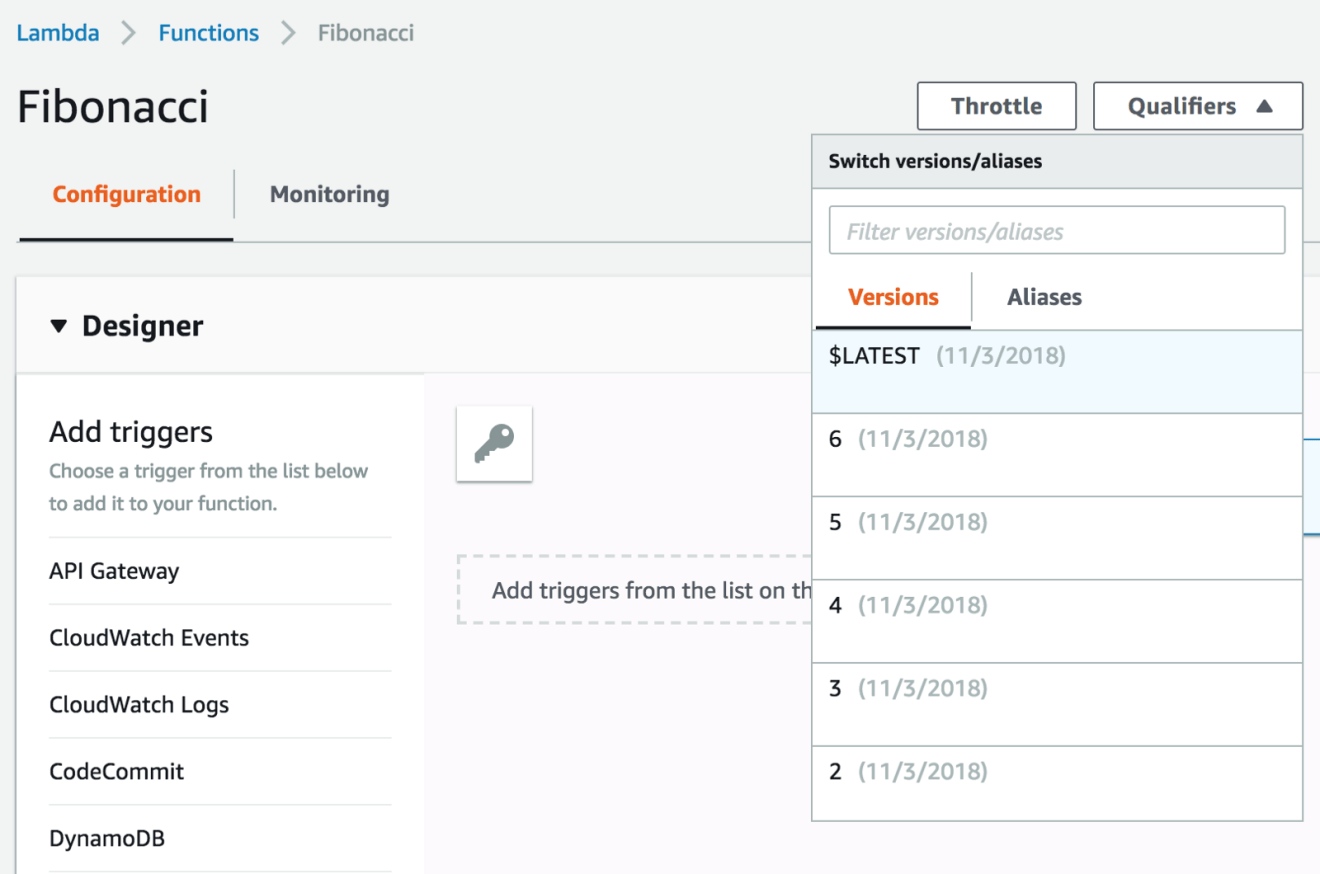
As a result, a new version will be published based on the master branch source code:
However, in agile based environment (Extreme programming). The development team needs to release iterative versions of the system often to help the customer to gain confidence in the progress of the project, receive feedback and detect bugs in earlier stage of development. As a result, small releases can be frequent:
AWS services using Lambda functions as downstream resources (API Gateway as an example) need to be updated every-time a new version is published -> operational overhead and downtime. USE aliases !!!
The alias is a pointer to a specific version, it allows you to promote a function from one environment to another (such as staging to production). Aliases are mutable, unlike versions, which are immutable.
That being said, create an alias for the production environment that points to the latest version published using the AWS command line:
def commitID() { sh 'git rev-parse HEAD > .git/commitID' def commitID = readFile('.git/commitID').trim() sh 'rm .git/commitID' commitID }
Like what you’re reading? Check out my book and learn how to build, secure, deploy and manage production-ready Serverless applications in Golang with AWS Lambda.
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.
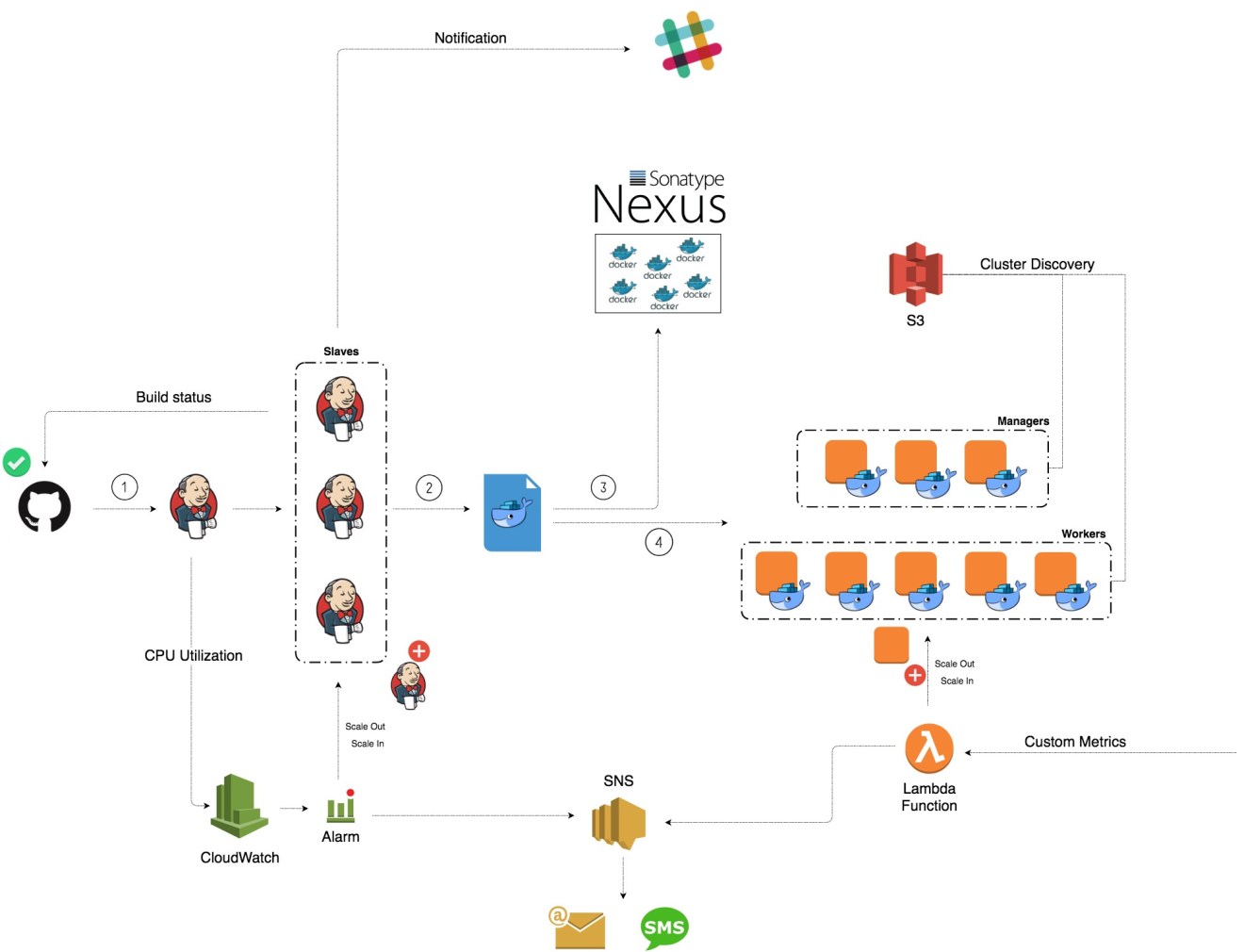
Few months ago, I gave a talk at Nexus User Conference 2018 on how to build a fully automated CI/CD platform on AWS using Terraform, Packer & Ansible. I illustrated how concepts like infrastructure as code, immutable infrastructure, serverless, cluster discovery, etc can be used to build a highly available and cost-effective pipeline. The platform I built is given in the following diagram:
The platform has a Jenkins cluster with a dedicated Jenkins master and workers inside an autoscaling group. Each push event to the code repository will trigger the Jenkins master which will schedule a new build on one of the available slaves. The slave will be responsible of running the unit and pre-integration tests, building the Docker image, storing the image to a private registry and deploying a container based on that image to Docker Swarm cluster.
On this post, I will walk through how to deploy the Jenkins cluster on AWS using top trending automation tools.
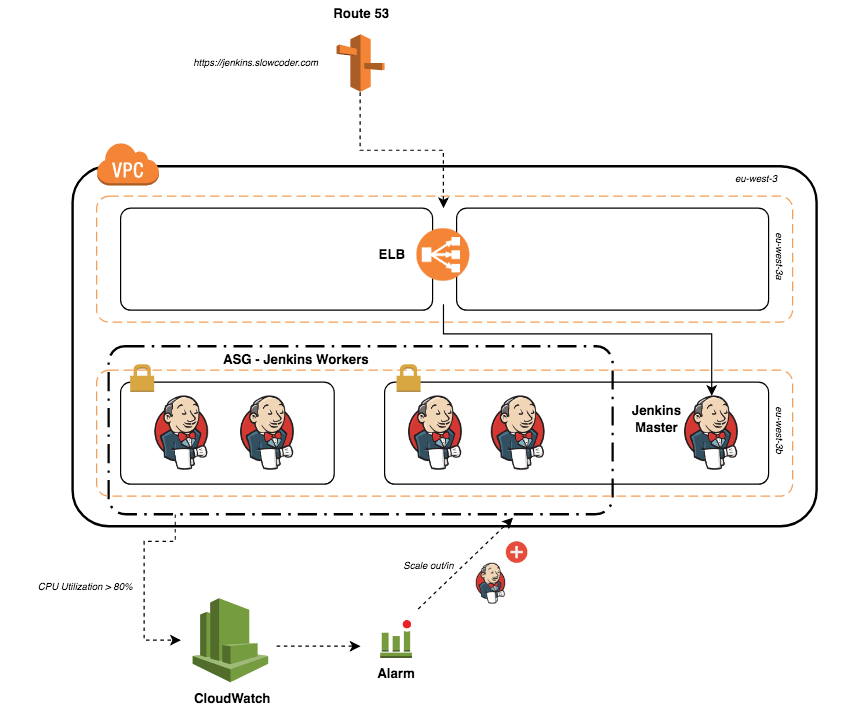
The cluster will be deployed into a VPC with 2 public and 2 private subnets across 2 availability zones. The stack will consists of an autoscaling group of Jenkins workers in a private subnets and a private instance for the Jenkins master sitting behind an elastic Load balancer. To add or remove Jenkins workers on-demand, the CPU utilisation of the ASG will be used to trigger a scale out (CPU > 80%) or scale in (CPU < 20%) event. (See figure below)
To get started, we will create 2 AMIs (Amazon Machine Image) for our instances. To do so, we will use Packer, which allows you to bake your own image.
The first AMI will be used to create the Jenkins master instance. The AMI uses the Amazon Linux Image as a base image and for provisioning part it uses a simple shell script:
It will install the latest stable version of Jenkins and configure its settings:
Create a Jenkins admin user.
Create a SSH, GitHub and Docker registry credentials.
Install all needed plugins (Pipeline, Git plugin, Multi-branch Project, etc).
Disable remote CLI, JNLP and unnecessary protocols.
Enable CSRF (Cross Site Request Forgery) protection.
Install Telegraf agent for collecting resource and Docker metrics.
The second AMI will be used to create the Jenkins workers, similarly to the first AMI, it will be using the Amazon Linux Image as a base image and a script to provision the instance:
A Jenkins worker requires the Java JDK environment and Git to be installed. In addition, the Docker community edition (building Docker images) and a data collector (monitoring) will be installed.
Now our Packer template files are defined, issue the following commands to start baking the AMIs:
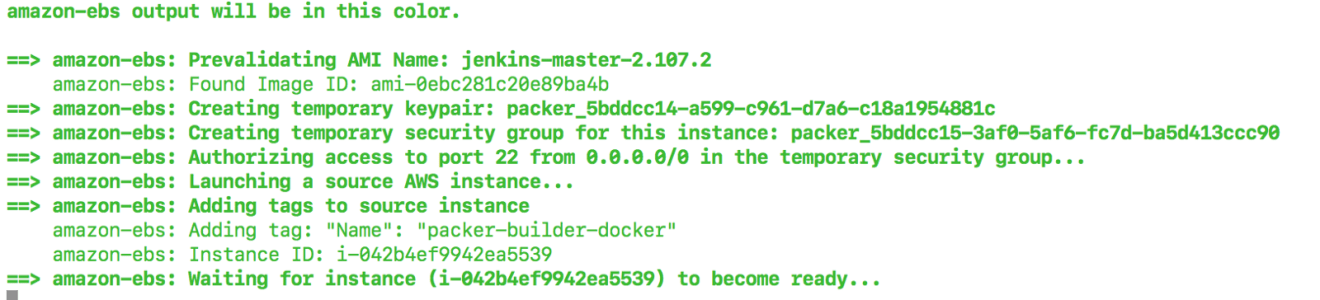
Packer will launch a temporary EC2 instance from the base image specified in the template file and provision the instance with the given shell script. Finally, it will create an image from the instance. The following is an example of the output:
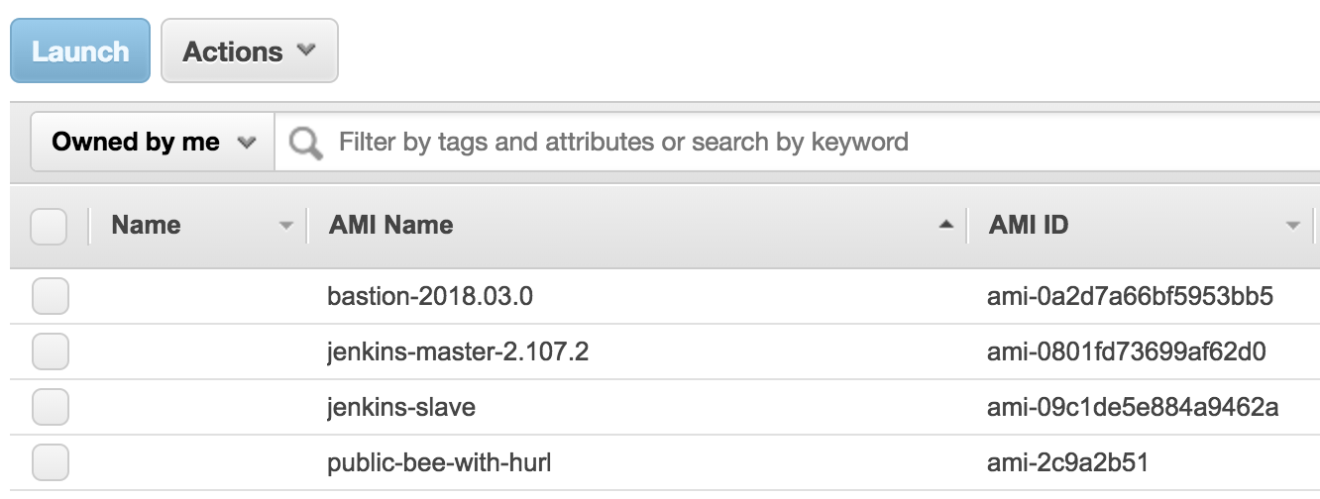
Sign in to AWS Management Console, navigate to “EC2 Dashboard” and click on “AMI”, 2 new AMIs should be created as below:
Now our AMIs are ready to use, let’s deploy our Jenkins cluster to AWS. To achieve that, we will use an infrastructure as code tool called Terraform, it allows you to describe your entire infrastructure in templates files.
I have divided each component of my infrastructure to a template file. The following template file is responsible of creating an EC2 instance from the Jenkins master’s AMI built earlier:
Another template file used as a reference to each AMI built with Packer:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
data "aws_ami" "jenkins-master" { most_recent = true owners = ["self"]
filter { name = "name" values = ["jenkins-master-2.107.2"] } }
data "aws_ami" "jenkins-slave" { most_recent = true owners = ["self"]
filter { name = "name" values = ["jenkins-slave"] } }
The Jenkins workers (aka slaves) will be inside an autoscaling group of a minimum of 3 instances. The instances will be created from a launch configuration based on the Jenkins slave’s AMI:
At boot time, the user-data script above will be invoked and the instance private IP address will be retrieved from the instance meta-data and a groovy script will be executed to make the node join the cluster:
1 2 3 4 5 6 7 8 9 10
data "template_file" "user_data_slave" { template = "${file("scripts/join-cluster.tpl")}"
Moreover, to be able to scale out and scale in instances on demand, I have defined 2 CloudWatch metric alarms based on the CPU utilisation of the autoscaling group:
Finally, an Elastic Load Balancer will be created in front of the Jenkins master’s instance and a new DNS record pointing to the ELB domain will be added to Route 53:
1 2 3 4 5 6 7 8 9 10 11
resource "aws_route53_record" "jenkins_master" { zone_id = "${var.hosted_zone_id}" name = "jenkins.slowcoder.com" type = "A"
alias { name = "${aws_elb.jenkins_elb.dns_name}" zone_id = "${aws_elb.jenkins_elb.zone_id}" evaluate_target_health = true } }
Once the stack is defined, provision the infrastructure with terraform apply command:
1 2 3 4 5 6 7 8
# Install the AWS provider plugin terraform int
# Dry-run check terraform plan
# Provision the infrastructure terraform apply --var-file=variables.tfvars
The command takes an additional parameter, a variables file with the AWS credentials and VPC settings (You can create a new VPC with Terraform from here):
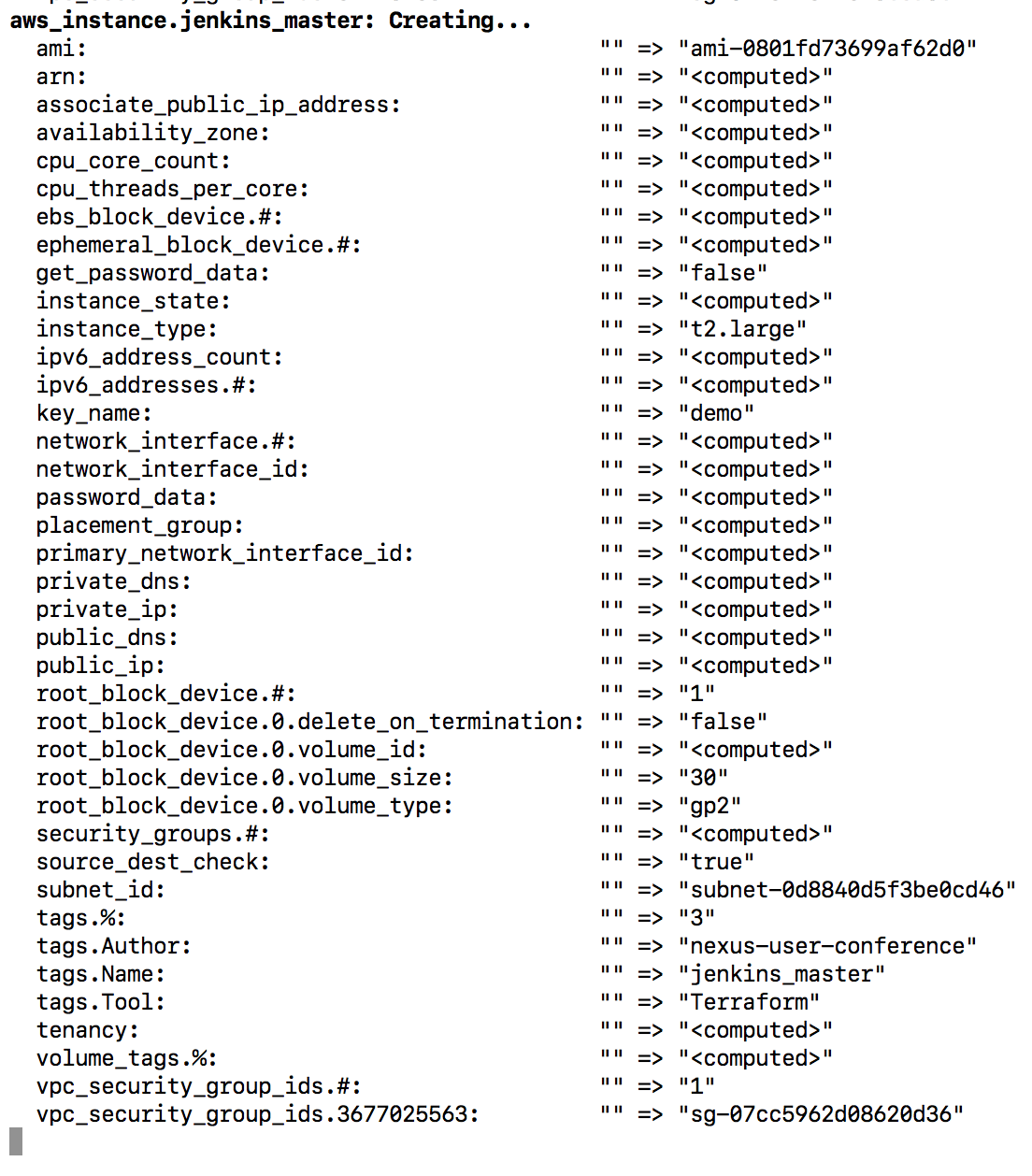
Terraform will display an execution plan (list of resources that will be created in advance), type yes to confirm and the stack will be created in few seconds:
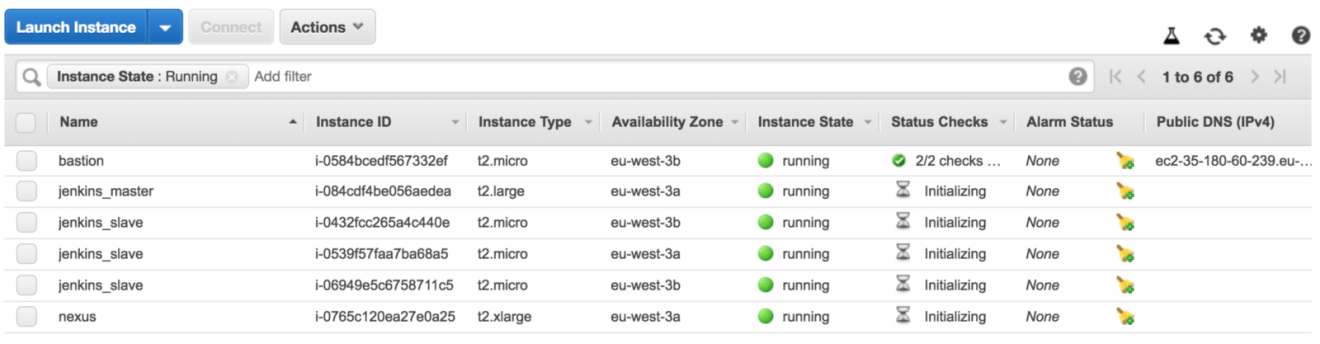
Jump back to EC2 dashboards, a list of EC2 instances will created:
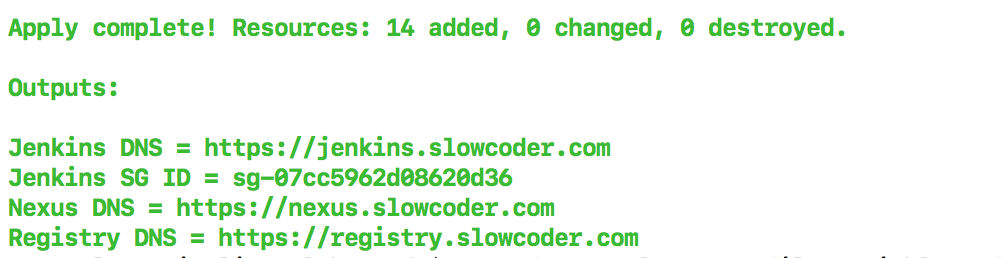
In the terminal session, under the Outputs section, the Jenkins URL will be displayed:
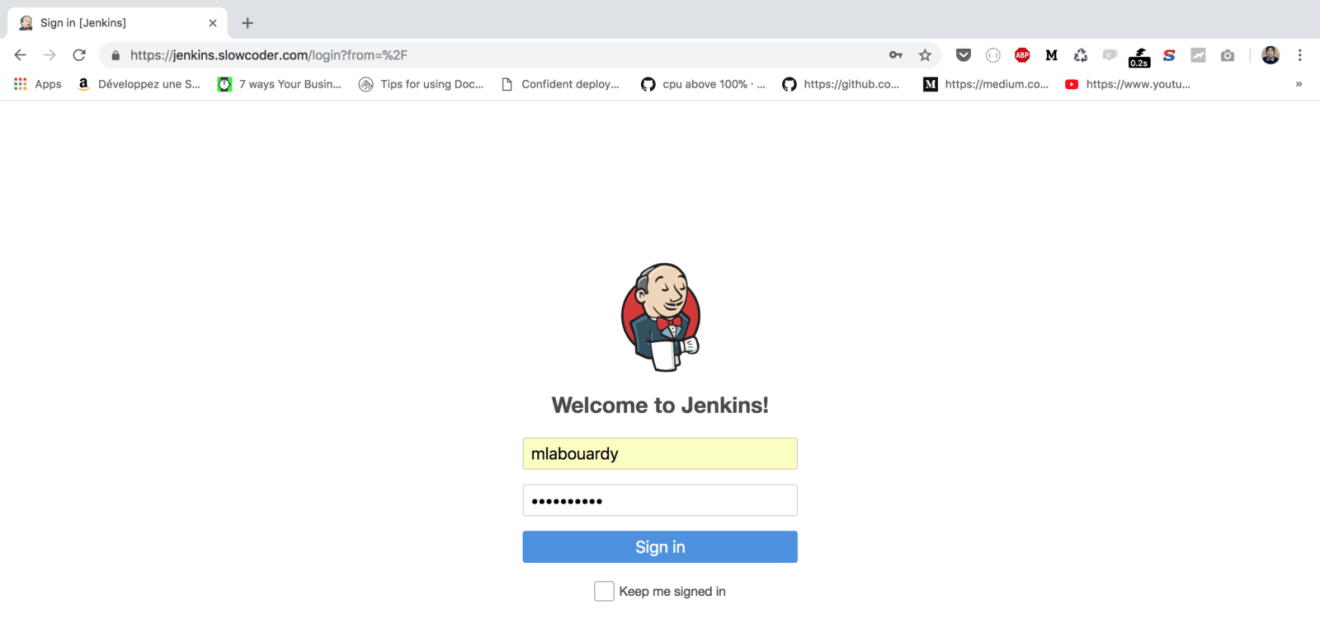
Point your favorite browser to the URL displayed, the Jenkins login screen will be displayed. Sign in using the credentials provided while baking the Jenkins master’s AMI:
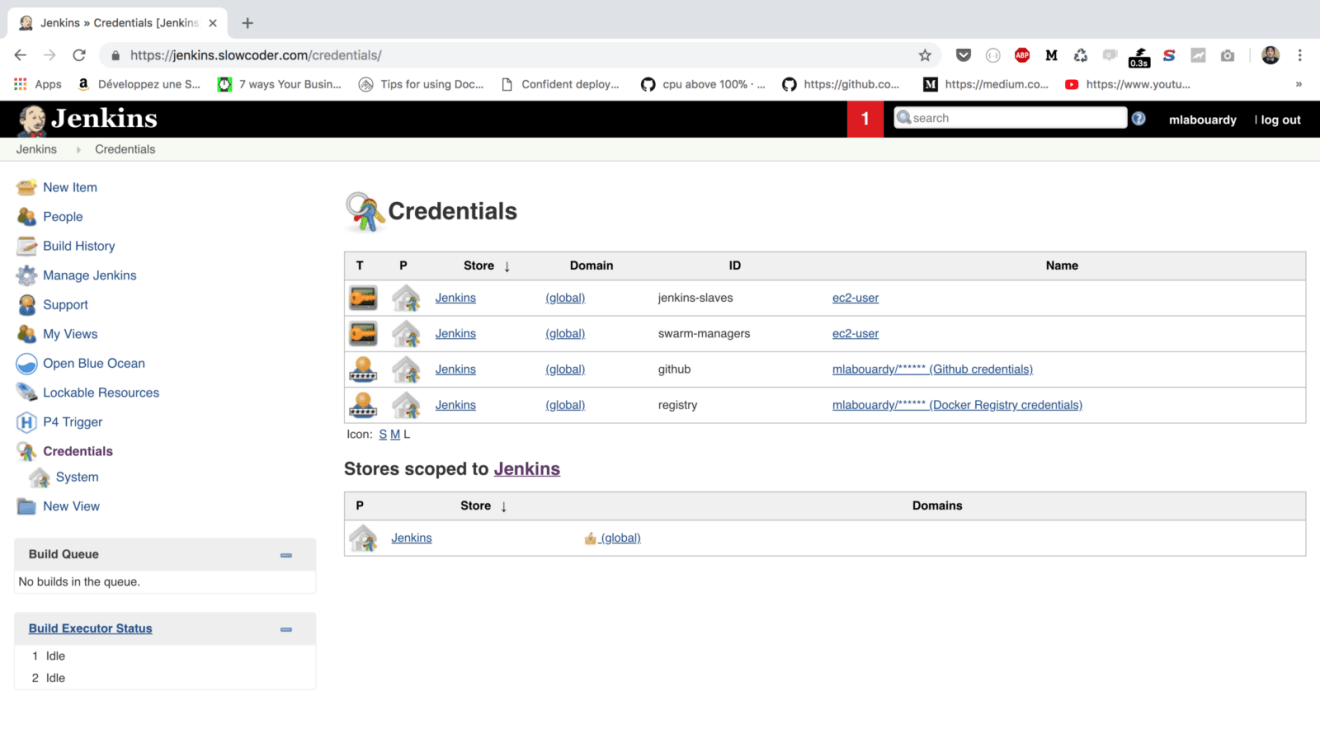
If you click on “Credentials” from the navigation pane, a set of credentials should be created out of the box:
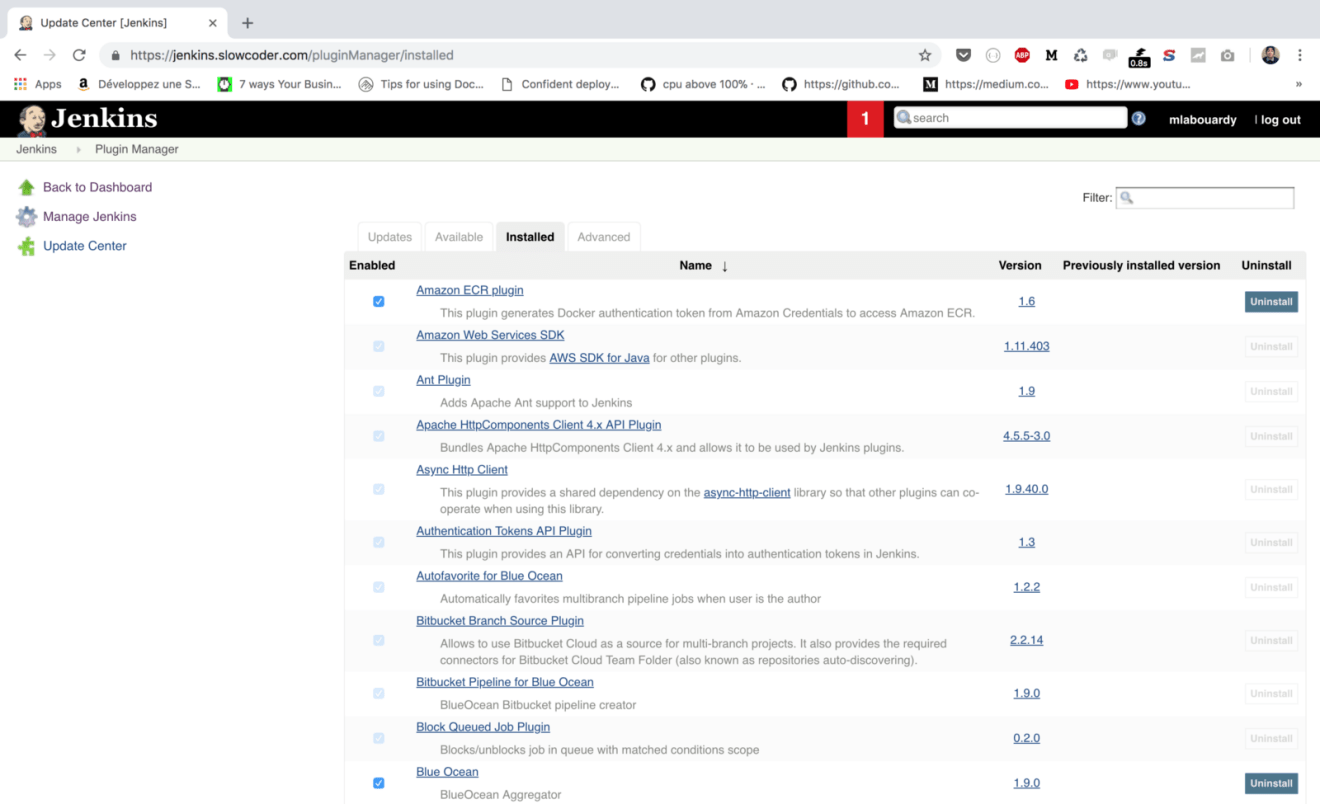
The same goes for “Plugins”, a list of needed packages will be installed also:
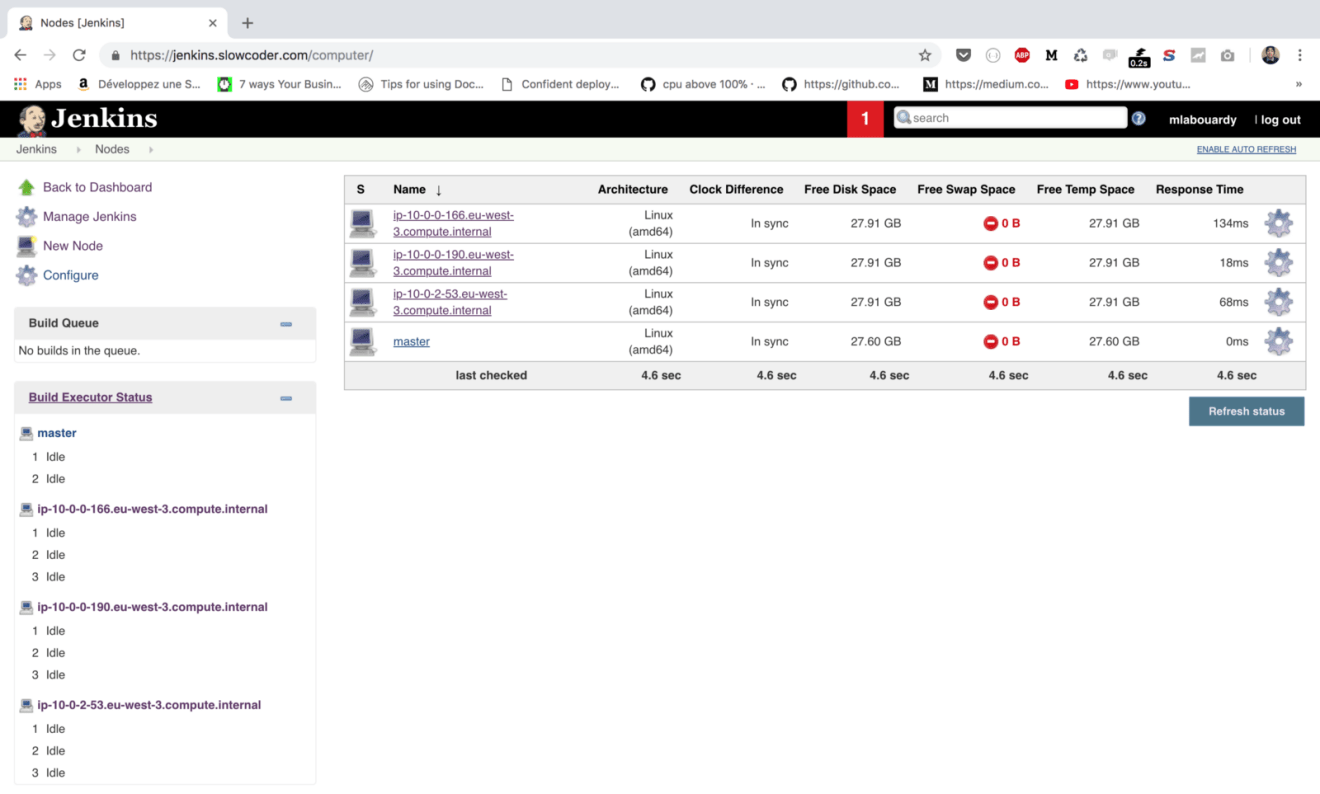
Once the Autoscaling group finished creating the EC2 instances, the instances will join the cluster automatically as you can see in the following screenshot:
You should now be ready to create your own CI/CD pipeline !
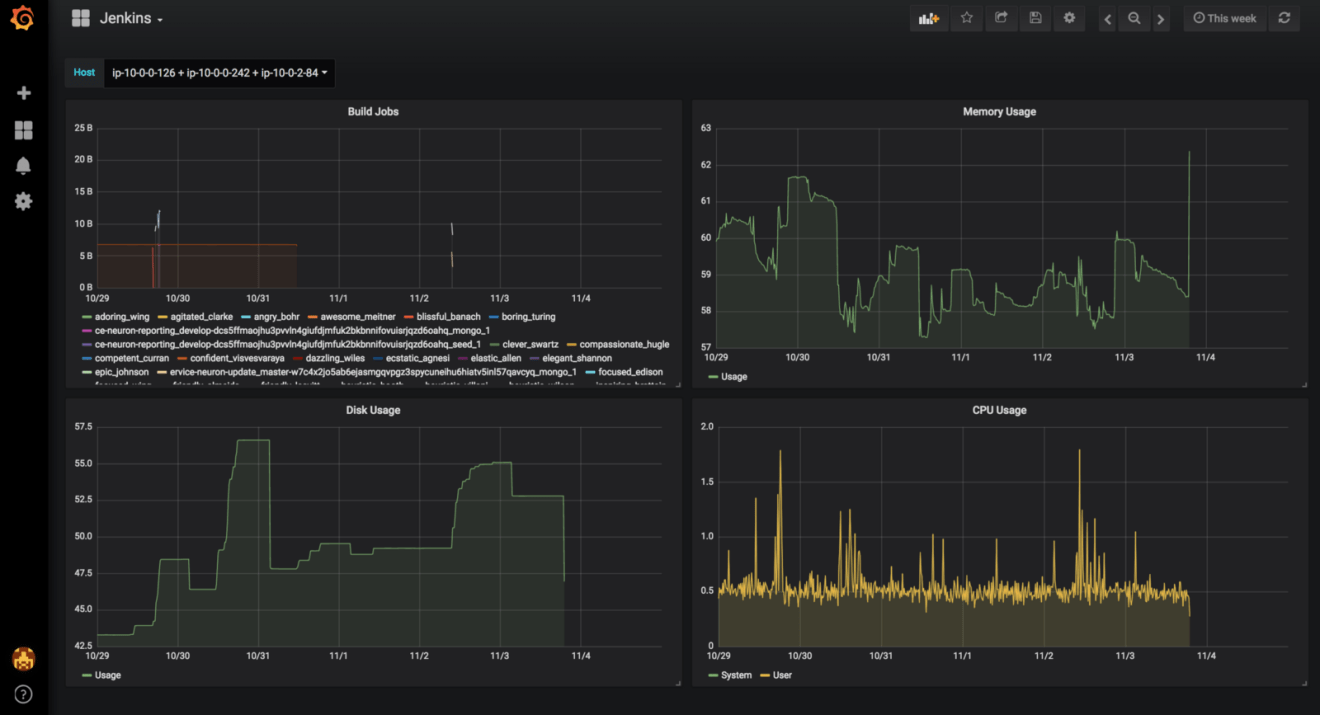
You can take this further and build a dynamic dashboard in your favorite visualisation tool like Grafana to monitor your cluster resource usage based on the metrics collected by the agent installed on each EC2 instance:
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.