




In analytics, where queries over hundreds of gigabytes are the norm, performance is paramount and has a direct effect on the productivity of your team: running a query for hours means days of iterations between business questions. At Foxintelligence, we needed to move from traditional relational databases, like Postgres and MySQL to columnar database solutions. While RDBS like MySQL is great for normal transactional operations, it has significant drawbacks when it comes to real-time analytics on large amount of data. We found Google BigQuery to deliver superior results significantly for usability, performance, and cost for almost all our analytical use-cases, especially at scale.
Both Amazon RedShift and Google BigQuery provide much of the same functionalities, there are some fundamental differences between how these two operate. So you need to pick the right solution based on your data and business.
Once we decided which data warehouse we will use, we had to replicate data from RDS MySQL to Google BigQuery. This post walks you through the process of creating a data pipeline to achieve the replication between the two systems.
We used AWS Data Pipeline to export data from MySQL and feed it to BigQuery. The figure below summarises the entire workflow:
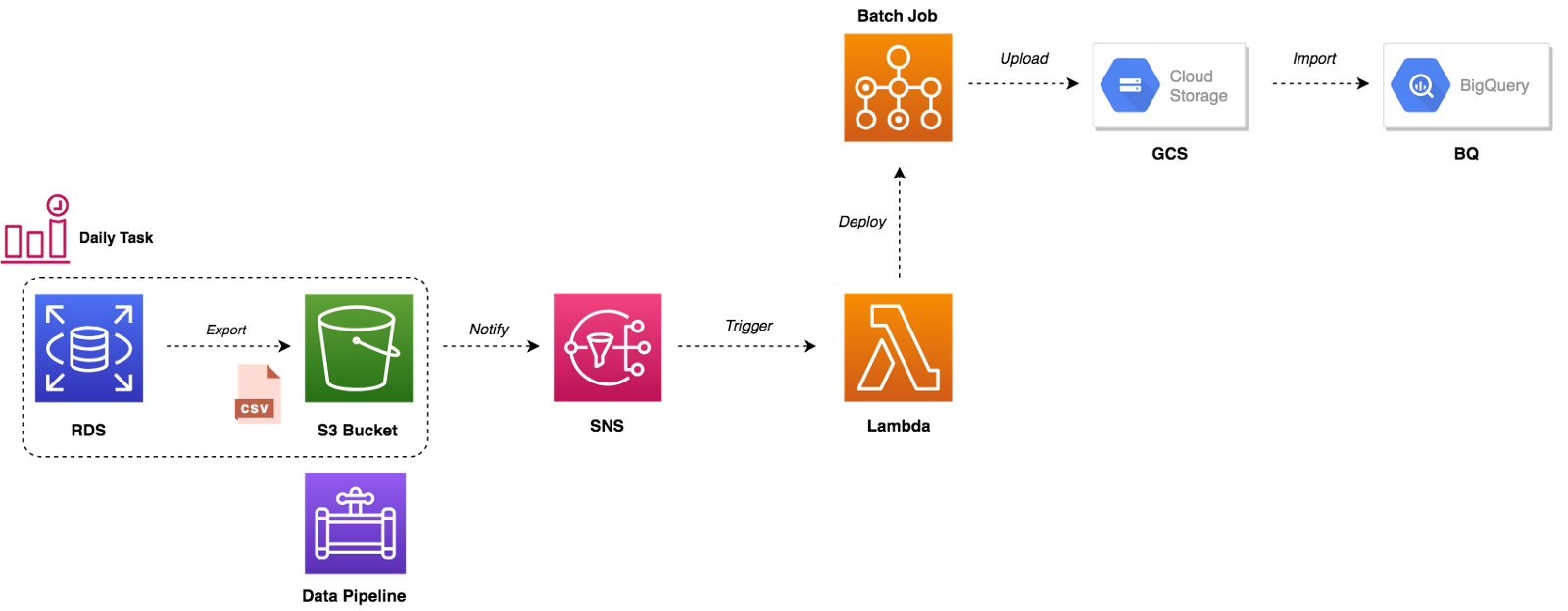
The pipeline starts based on a defined schedule and period, it launches a spot instance that will copy data from MySQL database to CSV files (split by table name) to an Amazon S3 bucket and then sending an Amazon SNS notification after the copy activity completes successfully. Following is our pipeline that accomplishes that:

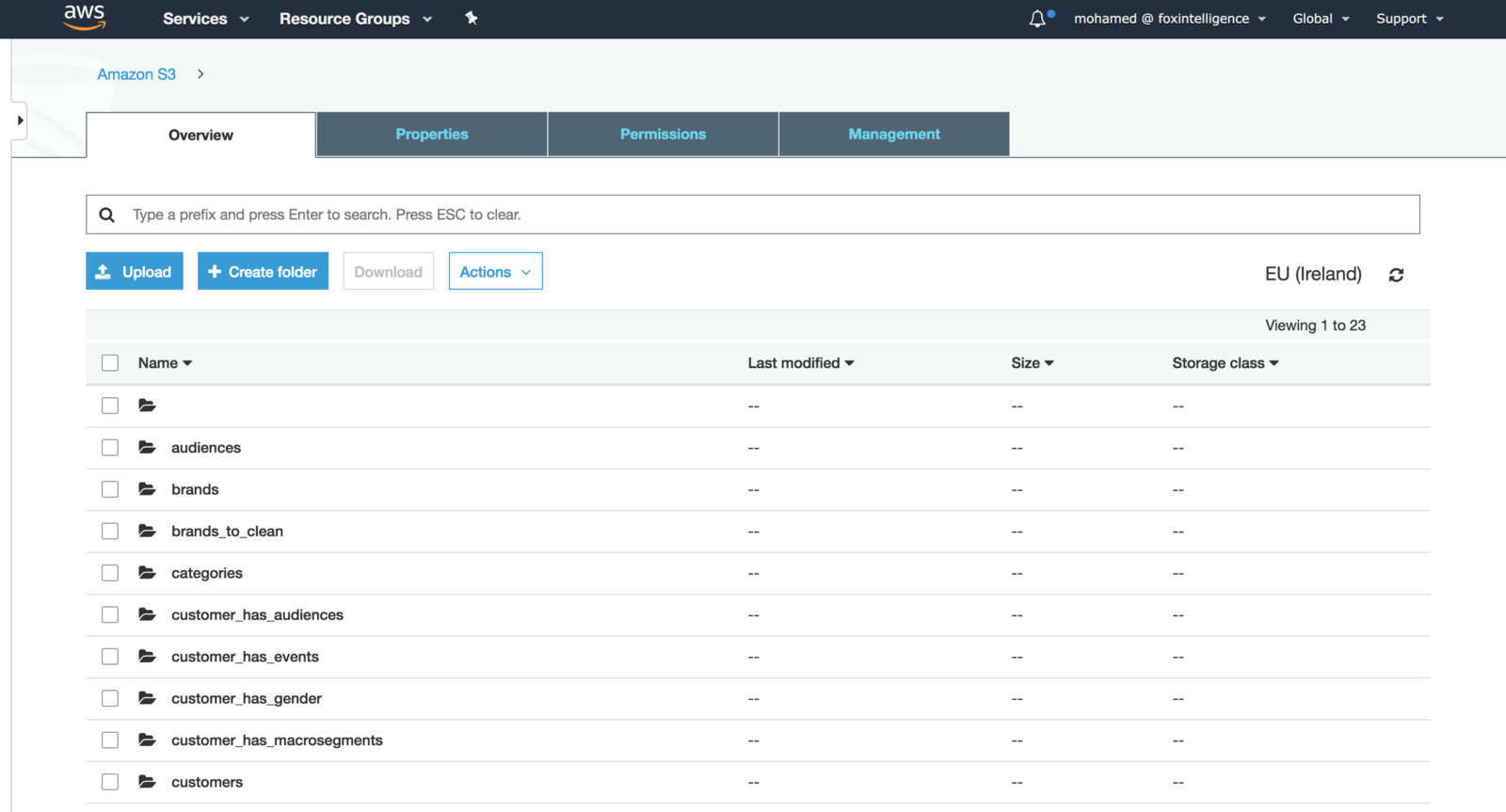
Once the pipeline is finished, CSV files will be generated in the output S3 bucket:
The SNS notification will trigger a Lambda function, it will deploy a batch job based on a Docker image stored on our private Docker registry. The container will upload CSV files from S3 to GCS and load data to BigQuery:
You can use Storage Transfer Service to easily migrate your data from Amazon S3 to Cloud Storage.
1 | #!/bin/bash |
We have written a Python script to clean up raw data (encoding issues), transform (map MySQL data types to BQ data types) and load CSV file to BigQuery:
1 | import mysql.connector |
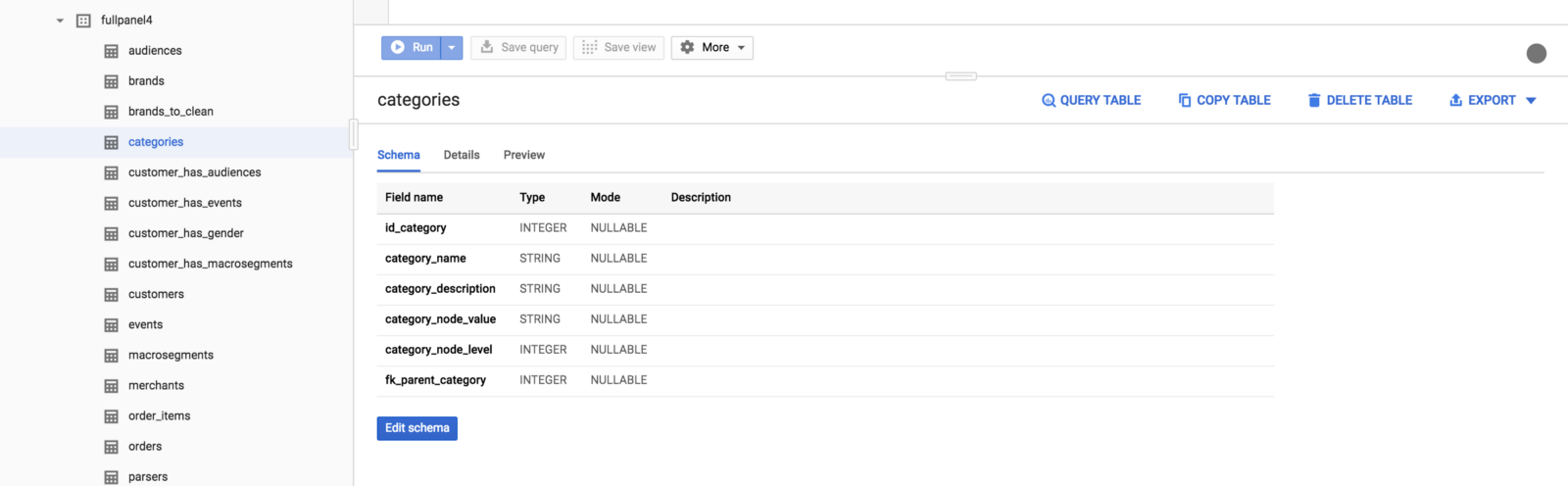
As a result, the tables will be imported to BigQuery:
While this solution worked like a charm, we didn’t stop there. Google Cloud announced the public beta release of BigQuery Data Transfer. This service allows you to automates data movement from multiple data sources like S3 or GCS to BigQuery on a scheduled, managed basis. So it was a great use case to test this service to manage recurring load jobs from Amazon S3 into BigQuery as shown in the figure below:
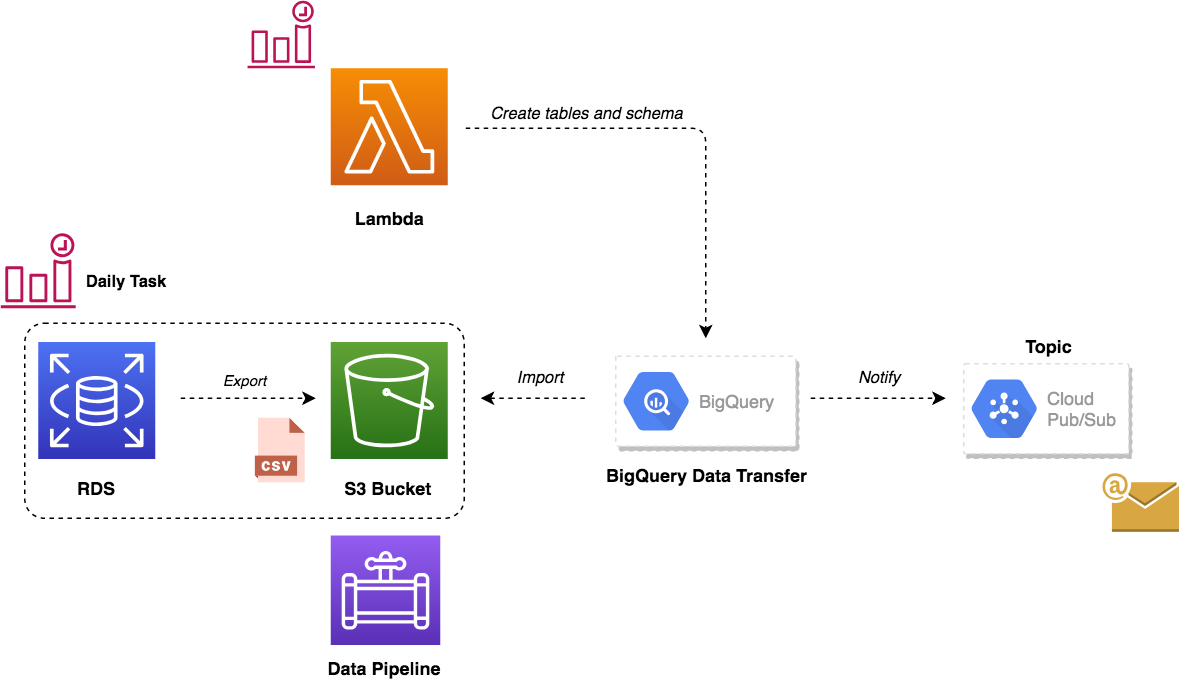
This services comes with some trade-offs such as Google BigQuery cannot create tables as part of data transfer process. Hence, a Lambda function was used to drop the old dataset, and create the destination tables and their schema in advance of running the transfer. The function handler code is self-explanatory:
1 | func handler(ctx context.Context) error { |
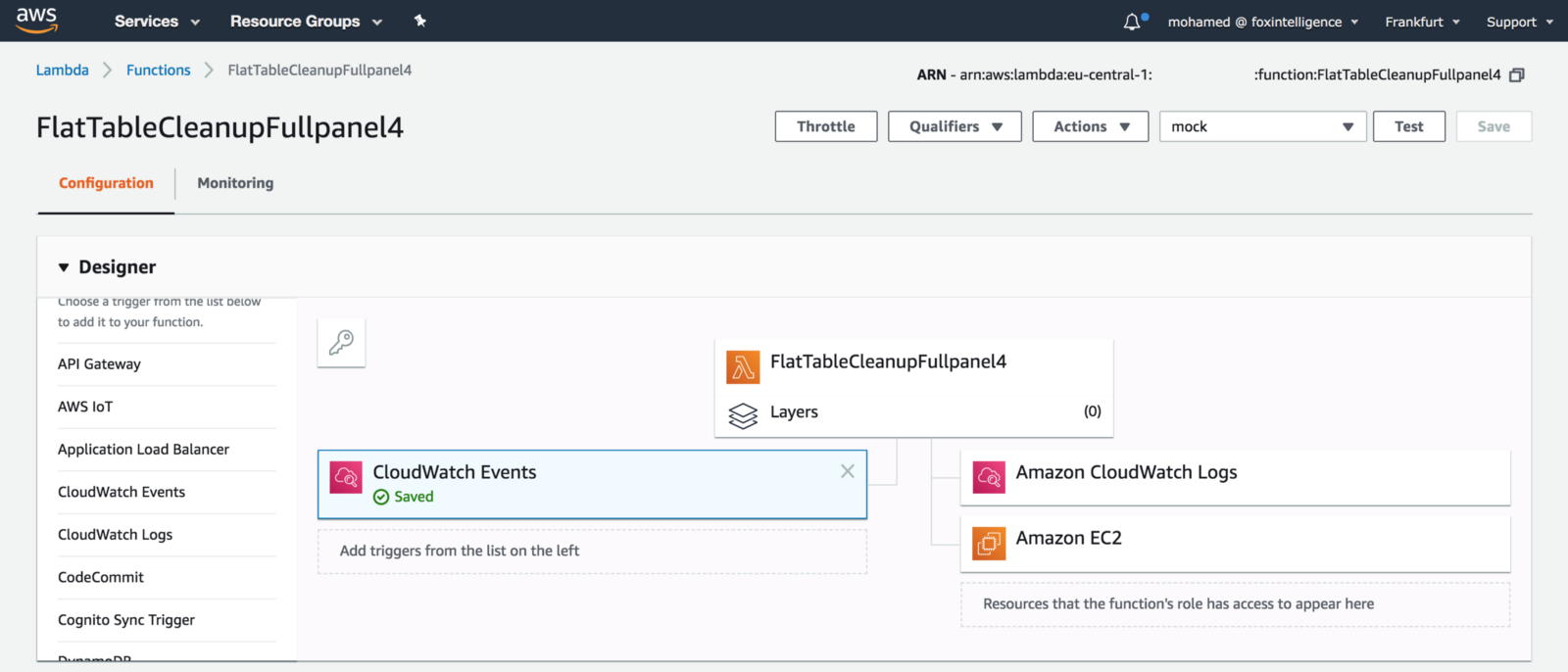
The function will be triggered by a CloudWatch Event, once the data pipeline finishes exporting CSV files:
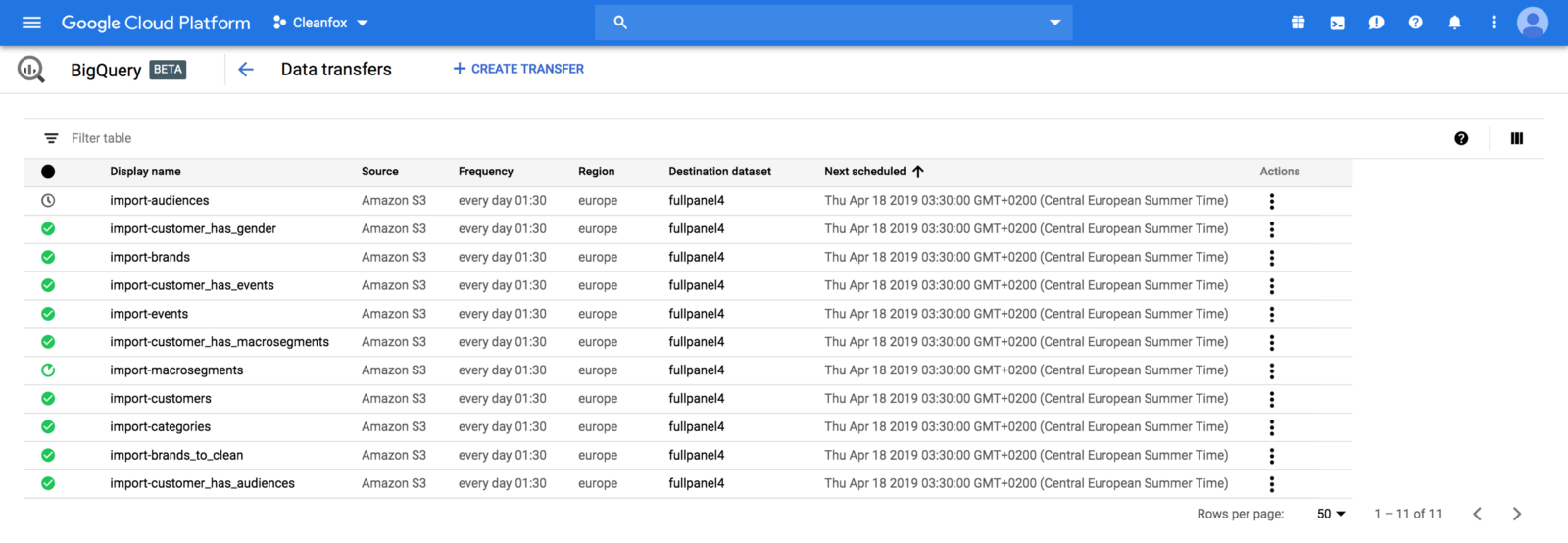
Finally, we created Transfer jobs for each table on BigQuery to load data from S3 bucket to BigQuery table:
Using Google BigQuery to store internally hundreds of gigabytes of data (soon terabytes) with the capability to analyse it in few seconds give us a massive push toward business intelligence and data-driven insights.
Like what you’re reading? Check out my book and learn how to build, secure, deploy and manage production-ready Serverless applications in Golang with AWS Lambda.
Drop your comments, feedback, or suggestions below — or connect with me directly on Twitter @mlabouardy.




